kafka
Kafka 是 Apache 基金会开源的高吞吐量分布式消息流平台,广泛用于日志采集、事件流处理和实时数据管道场景。本文介绍基于 CentOS 7 的 JDK、ZooKeeper 和 Kafka 的完整安装配置流程。
环境准备
system version: CentOS Linux release 7.6.1810 (Core)
java version: "1.8.0_311"
zookeeper verison: 3.7.0
kafka version: 2.13.3JDK安装
# 下载地址:
https://www.oracle.com/java/technologies/downloads/#java8
# 安装:
mkdir /usr/local/java/
tar zxvf jdk-8u311-linux-x64.tar.gz -C /usr/local/java
# 配置环境变量
vim /etc/profile
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source /etc/profile
ln -s /usr/local/java/jdk1.8.0_311/bin/java /usr/bin/ZooKeeper安装

ZooKeeper 是一个分布式的,开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现。它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如分布式同步,配置管理,集群管理,命名管理,队列管理。它被设计为易于编程,使用文件系统目录树作为数据模型。我们设计 ZooKeeper 的目的是为了减轻分布式应用程序所承担的协调任务 ZooKeeper 是集群的管理者,监视着集群中各节点的状态,根据节点提交的反馈进行下 一步合理的操作。最终,将简单易用的接口和功能稳定,性能高效的系统提供给用户;
# 安装
yum install -y ca-certificates
# 下载zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0.tar.gz
mkdir /usr/local/zookeeper
# 解压
tar zxvf apache-zookeeper-3.7.0-bin.tar.gz -C /usr/local/zookeeper/
cd /usr/local/zookeeper/
mv apache-zookeeper-3.7.0-bin/* . && rmdir apache-zookeeper-3.7.0-bin/
# 创建配置文件
cp conf/zoo_sample.cfg conf/zoo.cfg
mkdir {data,logs}
# 修改配置文件
[root@localhost zookeeper]# cat conf/zoo.cfg | grep -v ^#
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
dataLogDir=/usr/local/zookeeper/logs
clientPort=2181
# 常用命令
./bin/zkServer.sh start
./bin/zkServer.sh status
./bin/zkServer.sh stop
./bin/zkServer.sh restart
启动CLI
#
./bin/zkCli.sh Kakfa安装

相关术语:
Producers 生产者
Consumers 消费者
Broker:kafka 集群 服务器用于存储消息
topic 主题 相当于库 生产者消费者链接不同的主题存放不同且不相干的数据
# 下载地址
http://kafka.apache.org/downloads
# 解压
mkdir /usr/local/kafka/
tar zxvf kafka_2.13-3.0.0.tgz -C /usr/local/kafka/
cd /usr/local/kafka/
mv kafka_2.13-3.0.0/* . && rmdir kafka_2.13-3.0.0/
# 启动kafka
./bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
# 停止kafka
./bin/kafka-server-stop.sh
# 若本身没有部署zookeeper, 可以使用kafka自带的
./bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties &
# 测试kafka集群 创建 Topic
[root@localhost kafka]# ./bin/kafka-topics.sh --create --replication-factor 1 --partitions 1 --topic test --bootstrap-server 113.113.97.225:9092
[2021-10-28 16:14:45,994] INFO Creating topic test with configuration {} and initial partition assignment HashMap(0 -> ArrayBuffer(0)) (kafka.zk.AdminZkClient)
[2021-10-28 16:14:46,309] INFO [ReplicaFetcherManager on broker 0] Removed fetcher for partitions Set(test-0) (kafka.server.ReplicaFetcherManager)
[2021-10-28 16:14:46,515] INFO [LogLoader partition=test-0, dir=/tmp/kafka-logs] Loading producer state till offset 0 with message format version 2 (kafka.log.Log$)
[2021-10-28 16:14:46,559] INFO Created log for partition test-0 in /tmp/kafka-logs/test-0 with properties {} (kafka.log.LogManager)
[2021-10-28 16:14:46,566] INFO [Partition test-0 broker=0] No checkpointed highwatermark is found for partition test-0 (kafka.cluster.Partition)
[2021-10-28 16:14:46,569] INFO [Partition test-0 broker=0] Log loaded for partition test-0 with initial high watermark 0 (kafka.cluster.Partition)
Created topic test.
# 查看 topic 列表 返回上面创建的 test
[root@localhost kafka]# ./bin/kafka-topics.sh --list --bootstrap-server 113.113.97.225:9092
test
# 查看描述 topics 信息
[root@localhost kafka]# ./bin/kafka-topics.sh --describe --topic test --bootstrap-server 113.113.97.225:9092
Topic: test TopicId: 09sAAXNQToK1KQ5jAqyYHw PartitionCount: 1 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: test Partition: 0 Leader: 0 Replicas: 0 Isr: 0
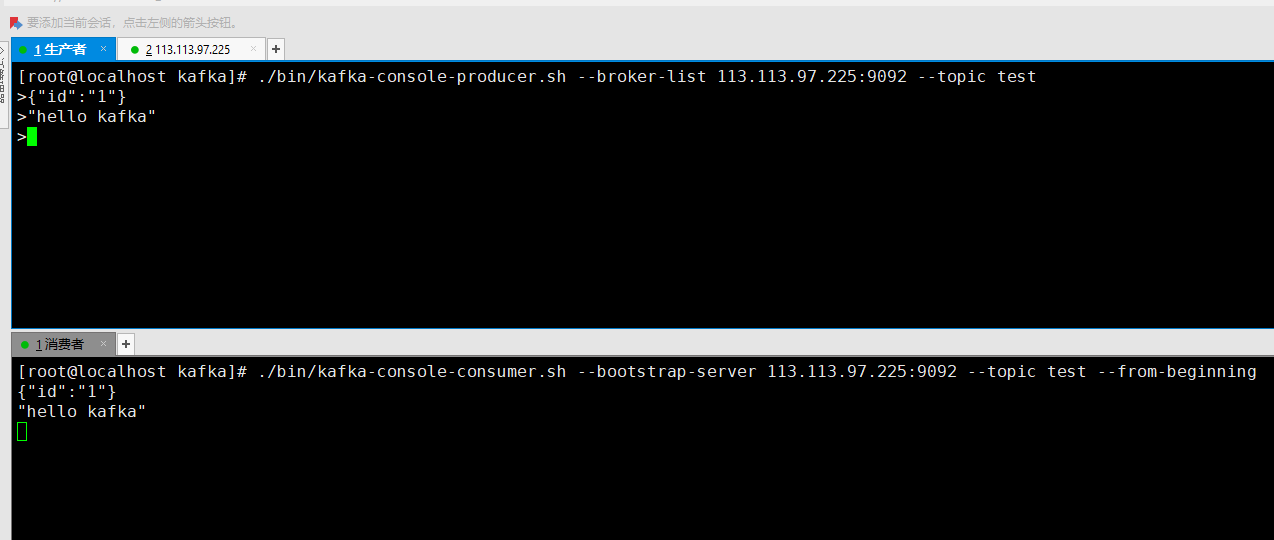
# 新建窗口 启动生产者
[root@localhost kafka]# ./bin/kafka-console-producer.sh --broker-list 113.113.97.225:9092 --topic test
# 启动消费者
./bin/kafka-console-consumer.sh --bootstrap-server 113.113.97.225:9092 --topic test --from-beginning当生产者产生数据的时候, 消费者同步显示
Kafka 高可用部署
先下载 Kafka 二进制文件:
$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.5.0/kafka_2.12-2.5.0.tgz解压并重命名:
$ tar zxvf kafka_2.12-2.5.0.tgz
$ sudo mv kafka_2.12-2.5.0 /opt/kafka编辑配置文件 config/server.properties :
broker.id=0
listeners=PLAINTEXT://fueltank-1:9092
advertised.listeners=PLAINTEXT://fueltank-1:9092
log.dirs=/mnt/vde/kafka
zookeeper.connect=fueltank-1:2181,fueltank-2:2181,fueltank-3:2181按照这个套路再为其他两台修改配置。
创建数据目录:
$ sudo mkdir -p /mnt/vde/kafka/log
$ sudo chown -R admin:admin /mnt/vde/kafka然后在每台机器上都执行:
$ ./bin/kafka-server-start.sh config/server.properties或者后台启动:
$ ./bin/kafka-server-start.sh -daemon config/server.properties通过 ZooKeeper 查看 Kafka 具有几个点:
$ ./bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 2] ls /brokers/ids
[0, 1, 2]查看所有 topics:
[zk: localhost:2181(CONNECTED) 3] ls /brokers/topics配置记录
broker.id=2
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://aitou.push2.bbdservice.net:9092
advertised.host.name=125.65.43.194
broker.id=3
listeners=PLAINTEXT://0.0.0.0:9092
advertised.listeners=PLAINTEXT://aitou.push3.bbdservice.net:9092
advertised.host.name=125.65.43.195Python调用kafka
# 官方文档
https://kafka-python.readthedocs.io/en/master/index.html
# 安装
pip install kafka-python消费者
from kafka import KafkaConsumer
# To consume latest messages and auto-commit offsets
consumer = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers=['localhost:9092'])
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
# consume earliest available messages, don't commit offsets
KafkaConsumer(auto_offset_reset='earliest', enable_auto_commit=False)
# consume json messages
KafkaConsumer(value_deserializer=lambda m: json.loads(m.decode('ascii')))
# consume msgpack
KafkaConsumer(value_deserializer=msgpack.unpackb)
# StopIteration if no message after 1sec
KafkaConsumer(consumer_timeout_ms=1000)
# Subscribe to a regex topic pattern
consumer = KafkaConsumer()
consumer.subscribe(pattern='^awesome.*')
# Use multiple consumers in parallel w/ 0.9 kafka brokers
# typically you would run each on a different server / process / CPU
consumer1 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
consumer2 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')生产者
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['broker1:1234'])
# Asynchronous by default
future = producer.send('my-topic', b'raw_bytes')
# Block for 'synchronous' sends
try:
record_metadata = future.get(timeout=10)
except KafkaError:
# Decide what to do if produce request failed...
log.exception()
pass
# Successful result returns assigned partition and offset
print (record_metadata.topic)
print (record_metadata.partition)
print (record_metadata.offset)
# produce keyed messages to enable hashed partitioning
producer.send('my-topic', key=b'foo', value=b'bar')
# encode objects via msgpack
producer = KafkaProducer(value_serializer=msgpack.dumps)
producer.send('msgpack-topic', {'key': 'value'})
# produce json messages
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('json-topic', {'key': 'value'})
# produce asynchronously
for _ in range(100):
producer.send('my-topic', b'msg')
def on_send_success(record_metadata):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
def on_send_error(excp):
log.error('I am an errback', exc_info=excp)
# handle exception
# produce asynchronously with callbacks
producer.send('my-topic', b'raw_bytes').add_callback(on_send_success).add_errback(on_send_error)
# block until all async messages are sent
producer.flush()
# configure multiple retries
producer = KafkaProducer(retries=5)最后更新于