ceph存储
Cpeh
概述
Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能、高可靠性。Ceph其命名和UCSC(Ceph 的诞生地)的吉祥物有关,这个吉祥物是“Sammy”,一个香蕉色的蛞蝓,就是头足类中无壳的软体动物。这些有多触角的头足类动物,是对一个分布式文件系统高度并行的形象比喻。 其设计遵循了三个原则:数据与元数据的分离,动态的分布式的元数据管理,可靠统一的分布式对象存储机制。
基本架构
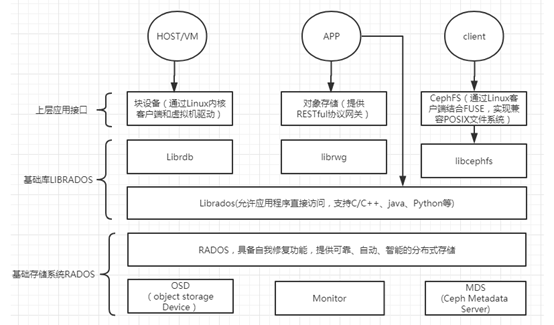
Ceph是一个高可用、易于管理、开源的分布式存储系统,可以在一套系统中同时提供对象存储、块存储以及文件存储服务。其主要由Ceph存储系统的核心RADOS以及块存储接口、对象存储接口和文件系统存储接口组成;
RADOS
所有其他客户端接口使用和部署的基础。由以下组件组成:
OSD:Object StorageDevice,提供数据实体存储资源;
Monitor:维护整个Ceph集群中各个节点的心跳信息,维持整个集群的全局状态;
MDS:Ceph Metadata Server,文件系统元数据服务节点。MDS也支持多台机器分布式的部署,以实现系统的高可用性。
典型的RADOS部署架构由少量的Monitor监控器以及大量的OSD存储设备组成,它能够在动态变化的基于异质结构的存储设备集群之上提供一种稳定的、可扩展的、高性能的单一逻辑对象存储接口。 Ceph客户端接口(Clients)
Ceph架构中除了底层基础RADOS之上的LIBRADOS、RADOSGW、RBD以及Ceph FS统一称为Ceph客户端接口。简而言之就是RADOSGW、RBD以及Ceph FS根据LIBRADOS提供的多编程语言接口开发。所以他们之间是一个阶梯级过渡的关系。
1.RADOSGW : Ceph对象存储网关,是一个底层基于librados向客户端提供RESTful接口的对象存储接口。目前Ceph支持两种API接口: S3.compatible:S3兼容的接口,提供与Amazon S3大部分RESTfuI API接口兼容的API接口。 Swift.compatible:提供与OpenStack Swift大部分接口兼容的API接口。Ceph的对象存储使用网关守护进程(radosgw)
2.RBD :一个数据块是一个字节序列(例如,一个512字节的数据块)。基于数据块存储接口最常见的介质,如硬盘,光盘,软盘,甚至是传统的9磁道的磁带的方式来存储数据。块设备接口的普及使得虚拟块设备成为构建像Ceph海量数据存储系统理想选择。 在一个Ceph的集群中, Ceph的块设备支持自动精简配置,调整大小和存储数据。Ceph的块设备可以充分利用 RADOS功能,实现如快照,复制和数据一致性。Ceph的RADOS块设备(即RBD)通过RADOS协议与内核模块或librbd的库进行交互。
3.Ceph FS :Ceph文件系统(CEPH FS)是一个POSIX兼容的文件系统,使用Ceph的存 储集群来存储其数据。CEPH FS的结构图如下所示:
存储类型
块存储
文件存储
对象存储
Ceph的存储过程
Ceph存储集群从客户端接收文件,每个文件都会被客户端切分成一个或多个对象,然后将这些对象进行分组,再根据一定的策略存储到集群的OSD节点中,其存储过程如图所示:
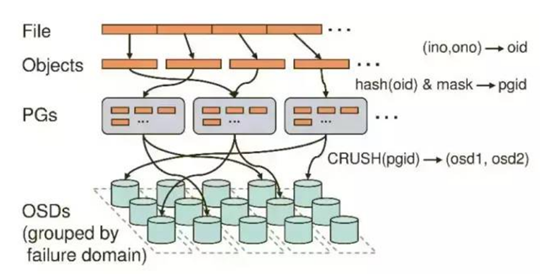
图中,对象的分发需要经过两个阶段的计算: 1、对象到PG的映射。PG(PlaccmentGroup)是对象的逻辑集合。PG是系统向OSD节点分发数据的基本单位,相同PG里的对象将被分发到相同的OSD节点中(一个主OSD节点多个备份OSD节点)。对象的PG是由对象ID号通过Hash算法,结合其他一些修正参数得到的。 2、PG到相应的OSD的映射,RADOS系统利用相应的哈希算法根据系统当前的状态以及PG的ID号,将各个PG分发到OSD集群中。
Ceph的优势
Ceph的核心RADOS通常是由少量的负责集群管理的Monitor进程和大量的负责数据存储的OSD进程构成,采用无中心节点的分布式架构,对数据进行分块多份存储。具有良好的扩展性和高可用性。
Ceph分布式文件系统提供了多种客户端,包括对象存储接口、块存储接口以及文件系统接口,具有广泛的适用性,并且客户端与存储数据的OSD设备直接进行数据交互,大大提高了数据的存取性能。
Ceph作为分布式文件系统,其能够在维护 POSIX 兼容性的同时加入了复制和容错功能。从2010 年 3 月底,以及可以在Linux 内核(从2.6.34版开始)中找到 Ceph 的身影,作为Linux的文件系统备选之一,Ceph.ko已经集成入Linux内核之中。Ceph 不仅仅是一个文件系统,还是一个有企业级功能的对象存储生态环境。
案例:搭建Ceph分布式存储
| 系统 | IP地址 | 主机名(登录用户) | 承载角色 |
|---|---|---|---|
| CentOS Linux release 7.9.2009 (Core) | 192.168.10.241 | master1 | admin-node |
| CentOS Linux release 7.9.2009 (Core) | 192.168.10.242 | master2 | mon osd mds |
| CentOS Linux release 7.9.2009 (Core) | 192.168.10.243 | master3 | mon osd mds |
| CentOS Linux release 7.9.2009 (Core) | 192.168.10.244 | node1 | mon osd mds |
| CentOS Linux release 7.9.2009 (Core) | 192.168.10.245 | node2 | mon osd mds |
| CentOS Linux release 7.9.2009 (Core) | 192.168.10.246 | node3 | ceph-client |
先决条件检测
# 安装python3
# 安装docker
# 时间同步服务器
# 安装lvm2
yum -y install python3 lvm2安装cephadm
# 使用curl获取独立脚本的最新版本。
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
# 添加权限
chmod a+x cephadm
# 尽管独立脚本足以启动集群,但将cephadm命令安装在主机上会很方便。
# 要安装提供该cephadm命令的软件包,请运行以下命令:
./cephadm add-repo --release octopus
./cephadm install
# 运行which以下命令确认它现在在您的PATH中:
[root@master1 ~]# which cephadm
/usr/sbin/cephadm
# 特定发行版安装
# 在 Ubuntu 中:
apt install -y cephadm
# 在 Fedora 中:
dnf -y install cephadm
# 在 SUSE 中:
zypper install -y cephadm创建新的ceph集群
# 创建新Ceph集群的第一步是在Ceph集群的第一台主机上运行命令。
# 在Ceph集群的第一台主机上运行命令的行为会创建Ceph集群的第一个“监视器守护进程”,并且该监视器守护进程需要一个 IP 地址。您必须将 Ceph 集群的第一台主机的 IP 地址传递给该命令,因此您需要知道该主机的IP地址。
# 如果有多个网络和接口,请确保选择一个可供访问 Ceph 集群的任何主机访问的网络和接口。
# 有关初始化的更多详情,可以运行 cephadm bootstrap -h
cephadm bootstrap --mon-ip 192.168.10.241
此命令将:
在本地主机上为新集群创建一个监视器和管理器守护进程。
为 Ceph 集群生成一个新的 SSH 密钥并将其添加到 root 用户的/root/.ssh/authorized_keys文件中。
将公钥的副本写入/etc/ceph/ceph.pub.
将最小配置文件写入/etc/ceph/ceph.conf. 需要此文件与新集群通信。
将client.admin管理(特权!)密钥的副本写入/etc/ceph/ceph.client.admin.keyring.
将_admin标签添加到引导主机。默认情况下,这个标签的任何主机将(也)获得的副本/etc/ceph/ceph.conf和 /etc/ceph/ceph.client.admin.keyring。cephadm初始化日志输出
[root@master1 ~]# cephadm bootstrap --mon-ip 192.168.10.241
Creating directory /etc/ceph for ceph.conf
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 9cad7e42-3d1a-11ec-ab43-faad9d5a0000
Verifying IP 192.168.10.241 port 3300 ...
Verifying IP 192.168.10.241 port 6789 ...
Mon IP 192.168.10.241 is in CIDR network 192.168.10.0/24
Pulling container image quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Wrote config to /etc/ceph/ceph.conf
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr not available, waiting (3/10)...
mgr not available, waiting (4/10)...
mgr not available, waiting (5/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host master1...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://master1:8443/
User: admin
Password: d64o9mtmor
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 9cad7e42-3d1a-11ec-ab43-faad9d5a0000 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.启用ceph cli
# 默认情况下,可以使用cephadm shell
# 要使用ceph命令,可以使用cephadm shell -- ceph -s
# 也可以安装ceph-common包,其中包含所有ceph命令,包括ceph、rbd、mount.ceph(用于挂载 CephFS 文件系统)等
cephadm add-repo --release octopus
cephadm install ceph-common
# 检查是否安装成功
[root@master1 ~]# ceph -v
ceph version 15.2.15 (2dfb18841cfecc2f7eb7eb2afd65986ca4d95985) octopus (stable)
# 使用以下ceph命令确认该命令可以连接到集群及其状态:
[root@master1 ~]# ceph status
cluster:
id: 9cad7e42-3d1a-11ec-ab43-faad9d5a0000
health: HEALTH_ERR
Module 'dashboard' has failed: OSError(98, 'Address already in use')
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum master1 (age 9m)
mgr: master1.jzdjri(active, since 7m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs: 添加主机
# 添加秘钥
ssh-copy-id -f -i /etc/ceph/ceph.pub root@master2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@master3
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node1
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node2
ssh-copy-id -f -i /etc/ceph/ceph.pub root@node3
# 告诉cpeh新增机器
ceph orch host add master2 192.168.10.242
ceph orch host add master3 192.168.10.243
ceph orch host add node1 192.168.10.244
ceph orch host add node2 192.168.10.245
ceph orch host add node3 192.168.10.246添加Mon
# 自动检测部署
ceph config set mon public_network 192.168.10.1/24
# 特定网络部署
ceph orch apply mon --unmanaged添加Osd
# 使用任何可用和未使用的设备
ceph orch apply osd --all-available-devices
# 使用指定主机上的设备
ceph orch daemon add osd master1:/dev/vdb
ceph orch daemon add osd master2:/dev/vdb
ceph orch daemon add osd master3:/dev/vdb
ceph orch daemon add osd node1:/dev/vdb
ceph orch daemon add osd node2:/dev/vdb
ceph orch daemon add osd node3:/dev/vdb
# 自动创建
ceph orch apply osd --all-available-devices集群状态检查
[root@master1 ~]# ceph status
cluster:
id: 9cad7e42-3d1a-11ec-ab43-faad9d5a0000
health: HEALTH_OK
services:
mon: 1 daemons, quorum master1 (age 15m)
mgr: master1.jzdjri(active, since 8m), standbys: master2.uwtwzp
osd: 6 osds: 6 up (since 15m), 6 in (since 80m)
data:
pools: 1 pools, 1 pgs
objects: 0 objects, 0 B
usage: 6.0 GiB used, 114 GiB / 120 GiB avail
pgs: 1 active+clean
# 获取dashborad地址
[root@master1 ~]# ceph mgr services
{
"dashboard": "http://master1:8080/",
"prometheus": "http://master1:9283/"
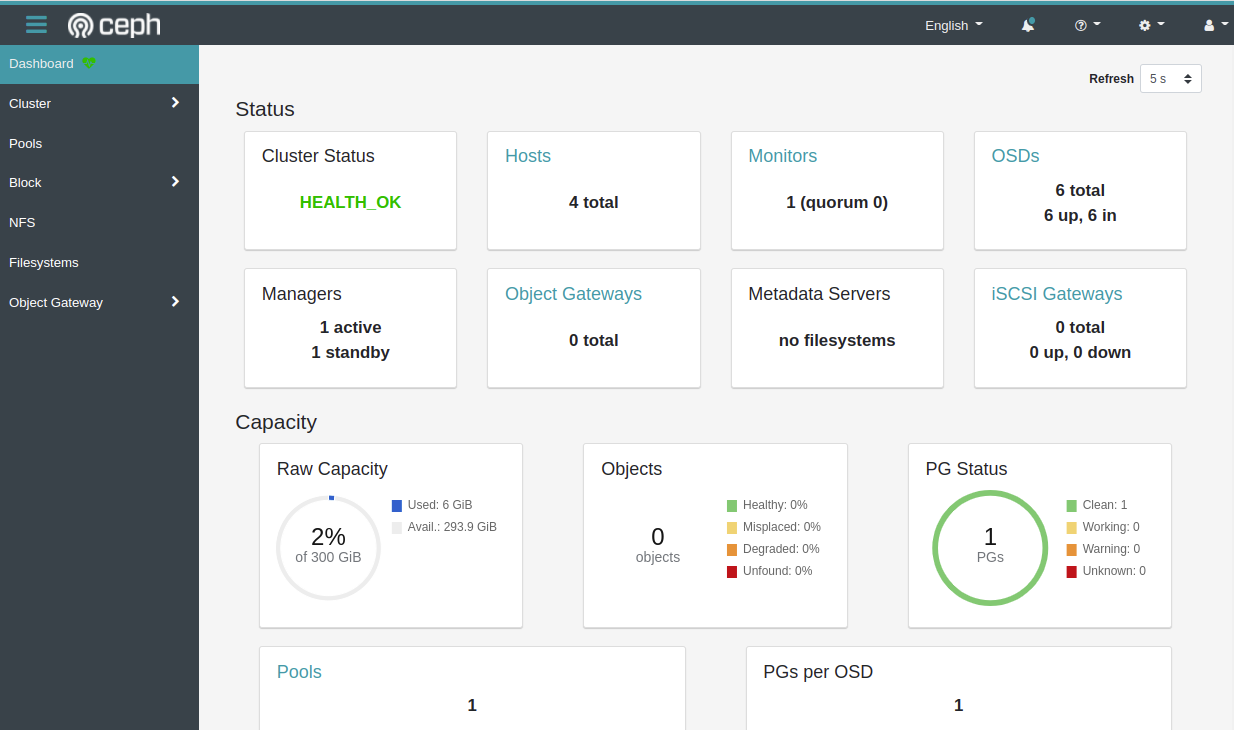
}访问web页面
账号: admin
密码: qwer1234!@#$QWER
URL地址:https://192.168.10.249:8443/#/dashboard
ceph文件系统
# 创建RADOS 池,一个用于数据,一个用于元数据
[root@master1 ~]# ceph osd pool create cephfs_data
pool 'cephfs_data' created
[root@master1 ~]# ceph osd pool create cephfs_metadata
pool 'cephfs_metadata' created
# 创建文件系统
# 格式 ceph fs new <fs_name> <metadata> <data>
[root@master1 ~]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 3 and data pool 2
[root@master1 ~]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
# 检查文件系统
[root@master1 ~]# ceph mds stat
cephfs:0
# 发现文件系统并未启动,获取详细报错信息
[root@master1 ~]# ceph health detail
HEALTH_ERR 1 filesystem is offline; 1 filesystem is online with fewer MDS than max_mds
[ERR] MDS_ALL_DOWN: 1 filesystem is offline
fs cephfs is offline because no MDS is active for it.
[WRN] MDS_UP_LESS_THAN_MAX: 1 filesystem is online with fewer MDS than max_mds
fs cephfs has 0 MDS online, but wants 1
# 这是因为文件系统需要启动 ceph-mds
# ceph-mds 用来管理文件系统的元数据,只有文件系统才需要,对象储存和块储存都不需要。
# 在web管理页面,Cluster-->Service-->Create--> type mds 创建mds即可
# 挂载文件系统,name指代用户,需要系统中存在此用户,且有相关的权限才可
mount -t ceph 192.168.10.241:6789:/ /mnt/mycephfs -o name=admin
umount /mnt/mycephfs
# 持久挂载
192.168.10.241:6789:/ /mnt/ceph ceph name=admin,noatime,_netdev 0 2
# 若有多个文件系统,则使用以下方式
mount -t ceph :/ /mnt/mycephfs2 -o name=fs,fs=mycephfs2
# 更多权限管理请参考官方文档ceph块设备
# 列出池
ceph osd lspools
# 创建块设备池
[root@master1 ~]# ceph osd pool create ceph-rbd
pool 'ceph-rbd' created
# 初始化池以供RBD使用
rbd pool init ceph-rbd
# 创建块设备用户
ceph auth get-or-create client.rbp mon 'profile rbd' osd 'profile rbd pool=vms, profile rbd-read-only pool=images' mgr 'profile rbd pool=images' > /etc/ceph/ceph.client.rbp.keyring
# 创建设备映像,若不指定pool,则使用默认pool
rbd create --size 1024 ceph-rbd/bar
# 查看块设备映像
rbd ls {poolname}
# 查看池中延迟删除的的块设备
rbd trash ls {poolname}
# 调整块设备映像的大小
# 删除块设备映像
rbd rm {pool-name}/{image-name}ceph对象网关
OpenStack对接ceph块存储
# 创建池
ceph osd pool create volumes
ceph osd pool create images
ceph osd pool create backups
ceph osd pool create vms
# 新创建的池必须在使用前进行初始化
rbd pool init volumes
rbd pool init images
rbd pool init backups
rbd pool init vms
# 查看创建的池
ceph osd lspools
# 配置OpenStack Ceph客户端
# 在ceph集群的控制节点上执行,分别往计算节点,控制节点,镜像节点和存储节点复制文件
ssh {your-openstack-server} sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf
# ceph节点配置认证
## 创建glance用户及权限
ceph auth get-or-create client.glance mon 'profile rbd' osd 'profile rbd pool=images' mgr 'profile rbd pool=images' -o /etc/ceph/ceph.client.glance.keyring
## 创建cinder用户及权限
ceph auth get-or-create client.cinder mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images' mgr 'profile rbd pool=volumes, profile rbd pool=vms' -o /etc/ceph/ceph.client.cinder.keyring
## 创建cinder-backup用户及权限
ceph auth get-or-create client.cinder-backup mon 'profile rbd' osd 'profile rbd pool=backups' mgr 'profile rbd pool=backups' -o /etc/ceph/ceph.client.cinder-backup.keyring
## 创建nova用户及权限
ceph auth get-or-create client.nova mon 'profile rbd' osd 'profile rbd pool=volumes, profile rbd pool=vms, profile rbd-read-only pool=images,profile rbd pool=backups' mgr 'profile rbd pool=volumes, profile rbd pool=vms' -o /etc/ceph/ceph.client.nova.keyring
# 安装ceph客户端包
# 此操作在openstack节点执行,所有需要访问ceph集群的节点都需要安装
yum install -y python-rbd ceph-common
ceph auth get-or-create client.glance | ssh 192.168.10.241 sudo tee /etc/ceph/ceph.client.glance.keyring
ssh 192.168.10.241 sudo chown glance:glance /etc/ceph/ceph.client.glance.keyring
ceph auth get-or-create client.cinder | ssh 192.168.10.241 sudo tee /etc/ceph/ceph.client.cinder.keyring
ssh 192.168.10.241 sudo chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring
ceph auth get-or-create client.cinder-backup | ssh 192.168.10.241 sudo tee /etc/ceph/ceph.client.cinder-backup.keyring
ssh 192.168.10.241 sudo chown cinder:cinder /etc/ceph/ceph.client.cinder-backup.keyring
ceph auth get-key client.cinder | ssh 192.168.10.241 tee client.cinder.key
cat > secret.xml <<EOF
<secret ephemeral='no' private='no'>
<uuid>b68d66f9-2316-4a2c-b2a9-1a525abbbf32</uuid>
<usage type='ceph'>
<name>client.cinder secret</name>
</usage>
</secret>
EOF
sudo virsh secret-define --file secret.xml
sudo virsh secret-set-value --secret b68d66f9-2316-4a2c-b2a9-1a525abbbf32 --base64 $(cat client.cinder.key) && rm client.cinder.key secret.xml