云原生-Kubernetes
本文系统介绍 Kubernetes 的核心概念、集群架构及节点类型,帮助读者从零理解容器编排平台的设计思路,并掌握高可用集群的搭建与日常运维操作。
Kubernetes集群基本概念
什么是Kubernetes
- kubernetes(也称k8s或“kube”)是一款开源的容器编排平台,用于调度以及自动部署、管理和扩展容器化应用
- 该名字源于希腊语,意为"舵手"或"飞行员"
- 最初由Google工程师开发,后来于2014年开源
- 受Google内部集群管理系统Borg的启发
什么是Kubernetes集群
- 有效的Kubernetes部署称为集群,也就是一组运行Linux容器的主机
- 可以将Kubernetes集群可视化分为两个部分:控制平面与计算设备(或称为工作节点)
- 每个节点都是其自己的Linux环境,并且可以是物理机或虚拟机
- 每个节点都运行由若干容器组成的容器集
- 控制平面负责维护集群的预期状态,例如运行哪个应用以及使用哪个容器镜像,工作节点则负责应用和工作负载的实力运行
- 控制平面接受来自管理员(或DevOps团队)的命令,并将这些指令转发给工作节点
Docker可被视作由Kubernetes编排的容器运行时
Kubernetes集群的节点类型
由Master和Worker两类节点组成
Master:控制节点
Worker:工作节点
Kubernetes集群运行逻辑
Kubernetes将所有工作节点的资源集结在一起形成一台更加强大的“服务器”,称为Kuernetes集群
计算和存储接口通过Master之上的API Server暴露
客户端通过API提交应用程序的运行请求,而后由Master通过调度算法将其自动指派至某特定的工作节点以 Pod对象的形式运行
Master会自动处理因工作节点的添加、故障或移除等变动对Pod的影响
Kubernetes集群架构
Kubernetes属于典型的Server-Client形式的二层架构
Master主要由API Server、Controller-Manager和Scheduler三个组件,以及一个用于集群状态存储的Etcd存储服务组成,它们构成整个集群 的控制平面
而每个Node节点则主要包含Kubelet、Kube Proxy及容器运行时(docker是最为常用的实现)三个组件,它们承载运行各类应用容器
Kubernetes Master Components
API Server
整个集群的API网关,相关应用程序为kube-apiserver
基于http/https协议以REST风格提供,几乎所有功能全部抽象为“资源”及相关的“对象”
声明式API,用于只需要声明对象的“终态”,具体的业务逻辑由各资源相关的Controller负责完成
无状态,数据存储于etcd中
Cluster Store
集群状态数据存储系统,通常指的就是etcd
仅会同API Server交互
Controller Manager
负责实现客户端通过API提交的终态声明,相应应用程序为kube-controller-manager
由相关代码通过一系列步骤驱动API对象的“实际状态”接近或等同“期望状态”
- 工作于loop模式
Scheduler
调度器,负责为Pod挑选出(评估这一刻)最合适的运行节点
相关程序为kube-scheduler
Kubernetes Worker Components
Kubelet
Kubernetes集群于每个Worker节点上的代理,相应程序为kubelet
接收并执行Master发来的指令,管理由Scheduler绑定至当前节点上的Pod对象的容器
通过API Server接收Pod资源定义,或从节点本地目录中加载静态Pod配置
借助于兼容CRI的容器运行时管理和监控Pod相关的容器
Kube Proxy
运行于每个Worker节点上,专用于负责将Service资源的定义转为节点本地的实现
iptables模式:将Service资源的定义转为适配当前节点视角的iptables规则
ipvs模式:将Service资源的定义转为适配当前节点视角的ipvs和少量iptables规则
是打通Pod网络在Service网络的关键所在
Kubernetes Add-ons
负责扩展Kubernetes集群的功能的应用程序,通常以Pod形式托管运行于Kubernetes集群之上
必选插件
Network Plugin:网络插件,经由CNI接口,负责为Pod提供专用的通信网络,有多种实现
CoreOS Flannel
ProjectCalico
Cluster DNS:集群DNS服务器,负责服务注册、发现和名称解析,当下的实现是CoreDNS
重要插件
Ingress Controller:Ingress控制器,负责为Ingress资源提供具体的实现,实现http/https协议的七层路由和流量 调度,有多种实现,例如Ingress-Nginx、Contour等
Metrics Server:Node和Pod等相关组件的核心指标数据收集器,它接受实时查询,但不存储指标数据 ◼ Kubernetes Dashboard/Kuboard/Rainbond:基于Web的UI
Prometheus:指标监控系统
ELK/PLG:日集中式日志系统
OpenELB:适用于非云端部署的Kubernetes环境的负载均衡器,可利用BGP和ECMP协议达到性能最优和高可 用性
应用编排的基本工作逻辑
Pod和应用
Kubernetes本质上是“以应用为中心”的现代应用基础设施,Pod是其运行应用及应用调度的最小逻辑单元
- 本质上是共享Network、IPC和UTS名称空间以及存储资源的容器集
- 可将其想象成一台物理机或虚拟机,各容器就是该主机上的进程
- 各容器共享网络协议栈、网络设备、路由、IP地址和端口等,但Mount、PID和USER仍隔离
- 每个Pod上还可附加一个“存储卷(Volume)”作为该“主机”的外部存储,独立于Pod的生命周期,可由Pod内的 各容器共享
- 模拟“不可变基础设施”,删除后可通过资源清单重建
- 具有动态性,可容忍误删除或主机故障等异常
- 存储卷可以确保数据能超越Pod的生命周期
在设计上,仅应该将具有“超亲密”关系的应用分别以不同 容器的形式运行于同一Pod内部
为什么要设计Service资源
Pod具有动态性,其IP地址也会在基于配置清单重构后重新进行分配,因而需要服务发现机制的支撑
Kubernetes使用Service资源和DNS服务(CoreDNS)进行服务发现
- Service能够为一组提供了相同服务的Pod提供负载均衡机制,其IP地址(Service IP,也称为Cluster IP)即为客 户端流量入口
- 一个Service对象存在于集群中的各节点之上,不会因个别节点故障而丢失,可为Pod提供固定的前端入口
- Service使用标签选择器(Label Selector)筛选并匹配Pod对象上的标签(Label),从而发现Pod
- 仅具有符合其标签选择器筛选条件的标签的Pod才可 由Service对象作为后端端点使用
Pod和工作负载型控制器
Pod是运行应用的原子单元,其生命周期管理和健康状态监测由kubelet负责完成,而诸如更新、扩缩 容和重建等应用编排功能需要由专用的控制器实现,这类控制器即工作负载型控制器
- ReplicaSet和Deployment
- DaemonSet
- StatefulSet
- Job和CronJob
工作负载型控制器也通过标签选择器筛选Pod标签从而完成关联 工作负载型控制器的工作重心
- 确保选定的Pod精确符合期望的数量
- 数量不足时依据Pod模板创建,超出时销毁多余的对象
- 按配置定义进行扩容和缩容
- 依照策略和配置进行应用更新
部署并访问应用
部署应用
- 依照编排需求,选定合适类型的工作负载型控制器
- 创建工作负载型控制器对象,由其确保运行合适数量的Pod对象
- 创建Service对象,为该组Pod对象提供固定的访问入口
请求访问Service对象上的服务
- 集群内部的通信流量也称为东西向流量,客户端也是集群上的Pod对象
- Service同集群外部的客户端之间的通信流量称为南北向流量,客户端是集群外部的进程
- 另外,集群上的Pod也可能会与集群外部的服务进程通信
Kubernetes网络模型
Kubernetes集群上会存在三个分别用于节点、Pod和Service的网络
于worker上完成交汇
由节点内核中的路由模块,以及iptables/netfilter和ipvs等完成网络间的流量转发
节点网络
- 集群节点间的通信网络,并负责打通与集群外部端点间的通信
- 网络及各节点地址需要于Kubernetes部署前完成配置,非由Kubernetes管理,因而,需要由管理员手动进行, 或借助于主机虚拟化管理程序进行
Pod网络
- 为集群上的Pod对象提供的网络
- 虚拟网络,需要经由CNI网络插件实现,例如Flannel、Calico、Cilium等
Service网络
- 在部署Kubernetes集群时指定,各Service对象使用的地址将从该网络中分配
- Service对象的IP地址存在于其相关的iptables或ipvs规则中
- 由Kubernetes集群自行管理
kubernetes集群中的通信流量
Kubernetes网络中主要存在4种类型的通信流量
- 同一Pod内的容器间通信
- Pod间的通信
- Pod与Service间的通信
- 集群外部流量与Service间的通信
Pod网络需要借助于第三方兼容CNI规范的网络插件完成,这些插件需要满足以下功能要求
- 所有Pod间均可不经NAT机制而直接通信
- 所有节点均可不经NAT机制直接与所有Pod通信
- 所有Pod对象都位于同一平面网络中
常用命令
# 资源查看:
kubectl get TYPE # 列出指定类型下的所有资源对象
kubectl get TYPE NAME1 [NAME2 ...] # 查看指定类型下的特定资源对象,或列出指定几个资源对象
kubectl get TYPE1/NAME1 TYPE2/NAME2 ...
kubectl get all # 列出所有类型下的所有资源对象
# 显示格式:
-o json|yaml|name|wide|jsonpath|customed-columes
# 资源详情描述:
kubectl describe TYPE [NAME1 [NAME2 ...]]
# 删除资源对象:
kubectl delete TYPE NAME1 [NAME2 ...]
kubectl delete TYPE1/NAME1 TYPE2/NAME2 ...
kubectl delete -f /PATH/TO/manifest
...
# 常用选项:
-n, --namespace 指定名称空间
--force:强制删除
--grace-period=0
--dry-run=client 测试执行
-w 监视输出
--show-labels 显示对象上的标签
# 查看当前集群核心群组
kubectl api-resources
--api-group='authorization' # 指定群组名称
# 查看资源的具体格式:
kubectl explain Kind[.field...]
# 查看资源详细信息
kubectl describe TYPE集群部署
Kubernetes集群组件运行模式
独立组件模式
- 除Add-ons以外,各关键组件以二进制方式部署于节 点上,并运行于守护进程
- 各Add-ons以Pod形式运行
静态Pod模式
- 控制平面各组件以静态Pod对象运行于Master主机之上
- kubelet和docker以二进制部署,运行为守护进程
- kube-proxy等则以Pod形式运行
- k8s.gcr.io
安装工具
- 原生安装工具kubeadm
- CNCF认证的安装工具
kubeadm
Kubernetes社区提供的集群构建工具
- 负责执行构建一个最小化可用集群并将其启动等必要的基本步骤
- Kubernetes集群全生命周期管理工具,可用于实现集群的部署、升级/降级及卸载等
- kubeadm仅关心如何初始化并拉起一个集群
部署前提
使用kubeadm部署Kubernetes集群的前提条件
- 支持Kubernetes运行的Linux主机,例如Debian、RedHat及其变体等
- 每主机2GB以上的内存,以及2颗以上的CPU
- 各主机间能够通过网络正常通信,支持各节点位于不同的网络中
- 独占的hostname、MAC地址以及product_uuid,主机名能够正常解析
- 放行由Kubernetes使用到的各端口,或直接禁用iptables
- 禁用各主机的上的Swap设备
- 各主机时间同步
准备代理服务,以便接入registry.k8s.io,或根据部署过程提示的方法获取相应的Image
重要提示:
- kubeadm不仅支持集群部署,还支持集群升级、卸载、更新数字证书等功能
- 目前,kubeadm为各节点默认生成的SSL证书的有效期限为1年,在到期之前需要renew这些证书
集群需要开放的端口
# master节点
api-server 6443
kubelet 10250
kube-schduler 10251
kube-controller-manager 10252
# node节点
kubelet 10250
nodeport servicest 30000~32767Docker和Containerd
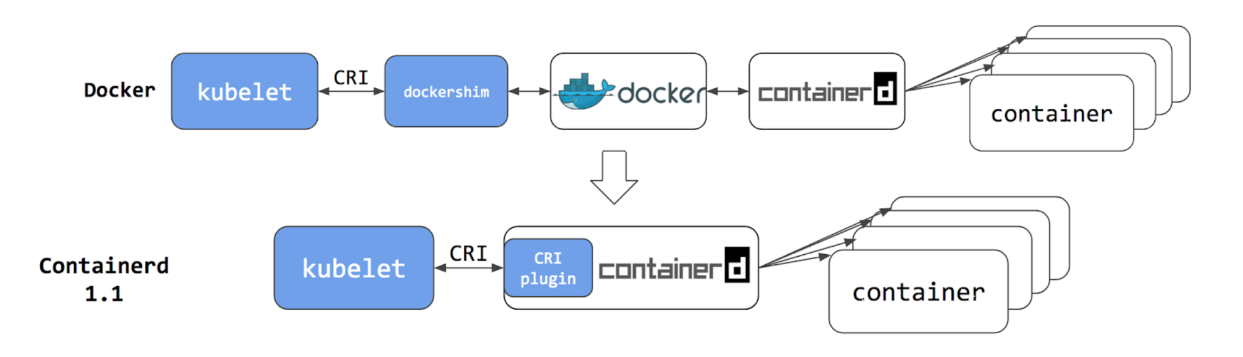
Kubernetes如何接入Docker和Containerd
调用链一:kubelet通过CRI调用dockershim,而后dockershim调用docker,再由docker通过containerd管理容器
- 用户基础好
- Kubernetes自1.24版开始,正式从kubelet中移除dockershim相关的代码,dockershim被弃用
- 但,Mirantis又提供了cri-docker项目,以kubelet外部独立运行的CRI服务替代dockershim
调用链二:kubelet通过CRI调用Containerd,而后Containerd直接管理容器
- 性能损耗低
- 不再支持docker客户端管理容器
集群部署步骤
验证各前提条件是否已然满足
在各节点上安装容器运行时
- 本示例选用Docker 24.0,CRI使用cri-dockerd
- 提示:部署时,需要在kubeadm的各命令上使用“–cri-socket”选项指定cri-dockerd进程的sock file路径
- 必要时,为Docker设置使用的代理服务
- 本示例选用Docker 24.0,CRI使用cri-dockerd
在各节点上安装kubeadm、kubelet和kubectl
创建集群
- 在控制平面的第一个节点上,使用kubeadm init命令拉起控制平面
- 会生成token以认证后续加入的节点
- (实验环境可选)将其它几个控制平面节点使用kubeadm join命令加入到控制平面集群中
- 提示:需要先从第一个控制平面节点上拿到CA及API Server等相应的证书
- 将各worker节点使用kubeadm join命令加入到集群中
- 确认各节点状态正常转为“Ready”
- 在控制平面的第一个节点上,使用kubeadm init命令拉起控制平面
# 初始化集群相关参数
kubeadm init --kubernetes-version=v1.28.2 --control-plane-endpoint="kubeapi.example.com" --pod-network-cidr=10.244.0.0/16 --service-cidr=10.96.0.0/12 --token-ttl=0 --image-repository=registry.aliyuncs.com/google_containers
# 参数说明:
--image-repository:指定要使用的镜像仓库,默认为registry.k8s.io;
--kubernetes-version:kubernetes程序组件的版本号,它必须要与安装的kubelet程序包的版本号相同;
--control-plane-endpoint:控制平面的固定访问端点,可以是IP地址或DNS名称,会被用于集群管理员及集群组件的kubeconfig配置文件的API Server的访问地址;单控制平面部署时可以不使用该选项;
--pod-network-cidr:Pod网络的地址范围,其值为CIDR格式的网络地址,通常,Flannel网络插件的默认为10.244.0.0/16,Project Calico插件的默认值为192.168.0.0/16;
--service-cidr:Service的网络地址范围,其值为CIDR格式的网络地址,默认为10.96.0.0/12;通常,仅Flannel一类的网络插件需要手动指定该地址;
--apiserver-advertise-address:apiserver通告给其他组件的IP地址,一般应该为Master节点的用于集群内部通信的IP地址,0.0.0.0表示节点上所有可用地址
--token-ttl:共享令牌(token)的过期时长,默认为24小时,0表示永不过期;为防止不安全存储等原因导致的令牌泄露危及集群安全,建议为其设定过期时长。未设定该选项时,在token过期后,若期望再向集群中加入其它节点,可以使用如下命令重新创建token,并生成节点加入命令。
# 安装网络组建
# flannel
kubectl apply -f https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
# calico
curl https://raw.githubusercontent.com/projectcalico/calico/v3.26.4/manifests/calico.yaml -O
kubectl apply -f calico.yaml集群管理相关操作
证书管理(kubeadm部署集群时设定的证书通常在一年后到期)
- 检查证书是否过期
- 命令:kubeadm certs check-expiration
- 手动更新证书
- 命令:kubeadm certs renew
- 提示:kubeadm会在控制平面升级时自动更新所有的证书
重置集群
- 提示:危险操作,请务必再三确认是否必须要执行该操作,尤其是在管理生产环境时要更加注意
- 命令:kubeadm reset
- 负责尽最大努力还原通过 ‘kubeadm init’ 或者 ‘kubeadm join’ 命令对主机所作的更改
- 一般需要配置“–cri-socket”选项使用
- 如果需要重置整个集群,一般要先reset各工作节点,而后再reset控制平面各节点,这与集群初始化的次序相反
- 最后还需一些清理操作,包括清理iptables规则或ipvs规则、删除相关的各文件等
集群升级
注意事项
- 升级前,务必要备份所有的重要组件,例如存储在数据库中应用层面的状态等;但kubeadm upgrade并不会影响工作负 载,它只会涉及Kubernetes集群的内部组件;
- 必须禁用Swap
整体步骤概览
- 先升级控制平面节点
- 而后再升级工作节点
各节点升级的步骤简介
- 升级kubeadm,但升级控制平面的第一个节点,同升级控制平面的其它节点以及各工作节点的命令有所不同
- 排空节点,而后升级kubelet和kubectl
具体的升级步骤
令牌过期后,向集群中添加新节点
- 生成新token
kubeadm token create- 获取CA证书的hash编码(SHA256)
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'- 将节点加入集群
kubeadm join kubeapi.magedu.com:6443 --token TOKEN --discovery-token-ca-cert-hash sha256:HASH更为简单的实现方式
方式一:直接生成将节点加入集群的命令
- kubeadm token create –print-join-command
方式二:分两步,先生成token,再生成命令
- TOKEN=$(kubeadm token generate)
- kubeadm token create ${TOKEN} –print-join-command
添加控制平面节点
先上传CA证书,并生成hash
- kubeadm init phase upload-certs –upload-certs
而后,生成添加控制平面节点的命令
- kubeadm token create –print-join-command –certificate-key $CERT_HASH
API资源规范
Kubernetes API Primitive
- 用于描述在Kubernetes上运行应用程序的基本组件,即俗称的Kubernetes对象(Object)
- 它们持久存储于API Server上,用于描述集群的状态
依据资源的主要功能作为分类标准,Kubernetes的API对象大体可分为如下几个类别
- 工作负载(Workload)
- 服务发现和负载均衡(Discovery & LB)
- 配置和存储(Config & Storage)
- 集群(Cluster)
- 元数据(Metadata)
“以应用为中心”
- Kubernetes API Primitive基本都是围绕一个核心目的而设计:如何更好地运行和丰富Pod资源,从而为容器化 应用提供更灵活和更完善的操作与管理组件
工作负载型资源负责应用编排
服务发现和负载均衡型资源完成服务注册、发现及流量调度
资源规范
绝大多数的Kubernetes对象都包含spec和status两个嵌套字段
- spec字段存储对象的期望状态(或称为应有状态)
- 由用户在创建时提供,随后也可按需进行更新(但有些属性并不支持就地更新机制)
- 不同资源类型的spec格式不尽相同
- status字段存储对象的实际状态(或称为当前状态)
- 由Kubernetes系统控制平面相关的组件负责实时维护和更新
对象元数据
- 名称、标签、注解和隶属的名称空间(不包括集群级别的资源)等
kind和apiVersion两个字段负责指明对象的类型(资源类型)元数据
- 前者用于指定类型标识
- 后者负责标明该类型所隶属的API群组(API Group)
API Server
- 基于HTTP(S)协议暴露了一个RESTful风格的API
- kubectl命令或其它UI通过该API查询或请求变更API对象的状态
- 施加于对象之上的基本操作包括增、删、改、查等
- 通过HTTP协议的GET、POST、DELETE和PUT等方法完成,而对应于kubectl命令,它们则是create、get、describe、 delete、patch和edit等子命令
API对象管理
创建对象时,必须向API Server提供描述其所需状态的对象规范、对象元数据及类型元数据
需要在请求报文的body中以JSON格式提供
- 用户也能够以YAML格式定义对象,提交给API Server后由其自行完成格式转换
资源规范的具体格式
- https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.22/
- 内建文档:kubectl explain 命令获取
- 参考现有资源对象:kubectl get TYPE/NAME -o {yaml|json}
# 资源规范:
apiVersion: API群组名和版本号
kind: 资源类型的名称
metadata: 对象元数据
name: 对象名称,惟一,同一类型下惟一(作用范围受限于资源类型隶属的空间)
namespace: 隶属的名称空间,默认为default
labels: 标签
key1: value1
key2: value2
...
annotations: 注释信息,注解
key1: value1
key2: value2
...
spec: 声明的期望状态
status:实际状态,由Controller负责达成实际效果,并回填该字段 API资源对象管理
使用客户端程序,对API Server的REST服务端点发请求
- 请求的body部分要遵循API资源规范
kubectl命令提供了三种类型的对象管理机制
- 指令式命令(Imperative commands)
- 直接作用于集群上的活动对象(Live objects)
- 适合在开发环境中完成一次性的操作任务
- 指令式对象配置(Imperative object configuration)
- 基于资源配置文件执行对象管理操作,但只能独立引用每个配置清单文件
- 可用于生产环境的管理任务
- 声明式对象配置(Declarative object configuration)
- 基于配置文件执行对象管理操作
- 可直接引用目录下的所有配置清单文件,也可直接作用于单个配置文件
资源对象管理的三种方式
# 方式一:
指令式命令:通过命令行选项定义要管理的资源对象
# 方式二:
指令式配置文件:
kubectl COMMAND -f FILE.yaml -f FILE.yml
kubectl COMMAND -f DIR/
需要明确的指明操作目的,如:create、get、delete、edit、replace
不支持幂等性
# 方式三:
声明式配置文件:
kubectl apply -f FILE.yaml -f FILE.yml
kubectl apply -f DIR/
一般只用于增加或修改,支持幂等
资源对象的CURD
增:
kubectl create 命令
kubectl create deployment nginx --image=nginx:1.22 --replicas=3 --dry-run=client -o yaml > deploy-nginx.yaml
kubectl create -f deploy-nginx.yaml
kubectl apply -f deploy-nginx.yaml
查:
kubectl get TYPE [NAME1 NAME2 ...]
kubectl get TYPE1/NAME1 TYPE2/NAME2 ...
kubectl describe:描述对象的详细的信息
kubectl describe TYPE NAME1 NAME2 ...
kubectl describe TYPE1/NAME1 TYPE2/NAME2 ...
删:
kubectl delete TYPE NAME1 NAME2 ...
kubectl delete TYPE1/NAME1 TYPE2/NAME2 ...
改:
kubectl edit TYPE NAME1 指令式命令—编排应用
- 仅打印资源清单
- kubectl create deployment demoapp –image=ikubernetes/demoapp:v1.0 –port=80 –dry-run=client –replicas=3 -o yaml
- 创建deployment对象
- kubectl create deployment demoapp –image=ikubernetes/demoapp:v1.0 –port=80 –replicas=3
- Deployment控制器确保deployment/demoapp中定义
- 了解完整的资源规范及状态
- kubectl get deployments [-o yaml|json]
- 了解Pod对象的相关信息
- kubectl get pods -l app=demoapp -o wide
指令式命令—创建Service对象
- 仅打印资源清单
- kubectl create service clusterip demoapp –tcp=80:80 –dry-run=client -o yaml
- 创建Service对象
- kubectl create service clusterip demoapp –tcp=80:80
- 了解Service的相关信息
- kubectl get services demoapp -o wide
- 访问Service
- demoappIP=$(kubectl get services demoapp -o jsonpath={.spec.clusterIP})
- curl $demoappIP
名称空间
名称空间(Namespace)
- 是Kubernetes集群提供对内部资源进行“软隔离”的机制,以方便用户管理和组织集群资源
- 可以将其想像成虚拟的"子集群"
管理名称空间
Kubernetes的名称空间可以划分为两种类型:
- 系统级名称空间:由Kubernetes集群默认创建,主要用来隔离系统级的资源对象
- 自定义名称空间:由用户按需创建
系统级名称空间
- default:默认的名称空间,为任何名称空间级别的资源提供的默认设定
- kube-system:Kubernetes集群自身组件及其它系统级组件使用的名称空间,Kubernetes自身的关键组件均部署在该名称空间中
- kube-public:公众开放的名称空间,所有用户(包括Anonymous)都可以读取内部的资源
- kube-node-lease:节点租约资源所用的名称空间
- 分布式系统通常使用“租约(Lease)”机制来锁定共享资源并协调集群成员之间的活动
- Kubernetes上的租约概念由API群组coordination.k8s.io群组下的Lease资源所承载,以支撑系统级别的功能需求,例如节点心跳(node heartbeats)和组件级的领导选举等
- Kubernetes集群的每个节点,在该名称空间下都有一个与节点名称同名的Lease资源对象
- kubectl -n kube-system get lease
所有的系统级名称空间均不能进行删除操作,而且除default外,其它三个也不应该用作业务应用的部署目标
需要使用名称空间的场景
环境管理:
- 需要在同一Kubernetes集群上隔离研发、预发和生产等一类的环境时,可以通过名称空间进行
隔离:
- 多个团队的不同产品线需要部署于同一Kubernetes集群时,可以使用名称空间进行隔离
资源控制
- 名称空间可用作资源配额的承载单位,从而限制其内部所有应用可以使用的CPU/Memory/PV各自的资源总和
- 需要在产品线或团队等隔离目标上分配各自总体可用的系统资源时,可通过名称空间实现
权限控制 - 基于RBAC鉴权体系,能够在名称空间级别进行权限配置
提高集群性能 - 进行资源搜索时,名称空间有利于Kubernetes API缩小查找范围,从而对减少搜索延迟和提升性能有一定的帮助
Pod
简介
什么是Pod:
- 一个或多个容器的集合,因而也可称为容器集,但却是Kubernetes调度、部署和运行应用的原子单元
- 另外封装的内容:可被该组容器共享的存储资源、网络协议栈及容器的运行控制策略等
- 依赖于pause容器事先创建出可被各应用容器共享的基础环境,它默认共享Network、IPC和UTS名称空间给各容器,PID名称空间也可以共享,但需要用户显式定义
Pod的组成形式:
**单容器Pod:**仅含有单个容器
**多容器Pod:**含有多个具有“超亲密”关系的容器
- 同一Pod内的所有容器都将运行于由Scheduler选定的同一个节点上
资源规范
一个极简的Pod定义,仅需要为其指定一个要运行的容器即可
需要给出该容器的名称和使用的Image,pause容器无需定义
示例:
# 基本Pod定义示例
apiVersion: v1
kind: Pod
metadata:
name: pod-demo
namespace: default
spec:
containers:
- name: demo
image: ikubernetes/demoapp:v1.0Pod运行状态
# 打印Pod完整的资源规范,通过status字段了解
kubectl get TYPE NAME -o yaml|json
例如:
kubectl get pods demoapp -o yaml
kubectl get pods demoapp -o json
# 打印Pod资源的详细状态
kubectl describe TYPE NAME
例如:
kubectl describe pods demoapp
# 获取Pod中容器应用的日志
kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER]
例如:
kubectl logs demoapp -c demoappPod的重启策略
Pod的重启策略决定Pod在终止以后是否应该重启,共有三种策略:
- **Always:**无论何种exit code,都要重启容器
- **OnFailure:**仅在exit code为非0值(即错误退出)时才重启容器
- **Never:**无论何种exit code,都不重启容器
镜像的下载策略
- Always:镜像标签为latest时,总是从指定的仓库中获取镜像;
- IfNotPresent:仅当本地没有对应镜像时,才从目标仓库中下载。
- Never:禁止从仓库中下载镜像,也就是说只能使用本地镜像;
Pod的相位
- Pending
- Running
- Succeeded
- Failed
- Unknown
容器的状态
- Waiting
- Running
- Terminated
- Unknown
配置Pod
通过环境变量向容器传递参数
- 环境变量是容器化应用的常用配置方式之一
- 在容器上嵌套使用env字段
- 每个环境变量需要通过name给出既定的名称
- 传递的值则定义在value字段上
# 示例一:MySQL Pod使用环境变量初始化管理员密码
apiVersion: v1
kind: Pod
metadata:
name: mydb
namespace: default
spec:
containers:
- name: mysql
image: mysql:8.0
env:
- name: MYSQL_ROOT_PASSWORD
value: "123456"
- name: MYSQL_DATABASE
value: wpdb
- name: MYSQL_USER
value: wpuser
- name: MYSQL_PASSWORD
value: magedu.com
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
resources:
requests:
cpu: "0.5"
memory: "100Mi"
limits:
cpu: "1"
memory: "200Mi"
# 示例二:WordPress Pod使用环境变量初始化
apiVersion: v1
kind: Pod
metadata:
name: wordpress
namespace: default
spec:
containers:
- name: wordpress
image: wordpress:5.7
env:
- name: WORDPRESS_DB_HOST
value: 123.123.123.123
- name: WORDPRESS_DB_NAME
value: wpdb
- name: WORDPRESS_DB_USER
value: wpuser
- name: WORDPRESS_DB_PASSWORD
value: magedu.com
readinessProbe:
httpGet:
port: 80
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
httpGet:
port: 80
initialDelaySeconds: 15
periodSeconds: 20
resources:
requests:
cpu: "0.5"
memory: "100Mi"
limits:
cpu: "1"
memory: "200Mi"
探针
容器式运行的应用类似于“黑盒”,为了便于平台对其进行监测,云原生应用应该输出用于监视自身 API
- 包括健康状态,指标,分布式跟踪和日志
- 至少应该提供用于健康状态检测的API

Pod支持的监测类型
- **Startup Probe:**启动探针,周期性运行,首次成功后退出,满足失败阙值会导致容器重启;
- **Liveness Probe:**存活探针,周期性运行,满足失败阈值会导致容器重启;
- **Readiness Probe:**就绪探针,周期性运行,满足失败阈值会导致以该Pod为后端实例之一的Service,将该Pod从可用后端列表中移除;
监测机制:
- Exec Action:根据指令命令的结果状态码判断
- TcpSocket Action:根据相应TCP套接字连接建立状态判定
- HTTPGet Action:根据指定https/http服务URL的响应结果判定
配置参数:
- **initialDelaySeconds:**容器启动后要等待多少秒后才启动启动、存活和就绪探针。 如果定义了启动探针,则存活探针和就绪探针的延迟将在启动探针已成功之后才开始计算。 如果
periodSeconds的值大于initialDelaySeconds,则initialDelaySeconds将被忽略。默认是 0 秒,最小值是 0。 - periodSeconds: 执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。
- timeoutSeconds: 探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。
- successThreshold: 探针在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。
- **failureThreshold:**探针连续失败了
failureThreshold次之后, Kubernetes 认为总体上检查已失败:容器状态未就绪、不健康、不活跃。 对于启动探针或存活探针而言,如果至少有failureThreshold个探针已失败, Kubernetes 会将容器视为不健康并为这个特定的容器触发重启操作。 kubelet 遵循该容器的terminationGracePeriodSeconds设置。 对于失败的就绪探针,kubelet 继续运行检查失败的容器,并继续运行更多探针; 因为检查失败,kubelet 将 Pod 的Ready状况设置为false。 - **terminationGracePeriodSeconds:**为 kubelet 配置从为失败的容器触发终止操作到强制容器运行时停止该容器之前等待的宽限时长。 默认值是继承 Pod 级别的
terminationGracePeriodSeconds值(如果不设置则为 30 秒),最小值为 1。
apiVersion: v1
kind: Pod
metadata:
name: pod-probe-demo
namespace: default
spec:
containers:
- name: demo
image: ikubernetes/demoapp:v1.0
imagePullPolicy: IfNotPresent
startupProbe:
exec:
command: ['/bin/sh','-c','test','"$(curl -s 127.0.0.1/livez)"=="OK"']
initialDelaySeconds: 0
failureThreshold: 3
periodSeconds: 2
livenessProbe:
httpGet:
path: '/livez'
port: 80
scheme: HTTP
initialDelaySeconds: 3
timeoutSeconds: 2
readinessProbe:
httpGet:
path: '/readyz'
port: 80
scheme: HTTP
initialDelaySeconds: 15
timeoutSeconds: 2
restartPolicy: Always定义 TCP 的存活探测
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: registry.k8s.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20如你所见,TCP 检测的配置和 HTTP 检测非常相似。 下面这个例子同时使用就绪和存活探针。kubelet 会在容器启动 15 秒后发送第一个就绪探针。 探针会尝试连接 goproxy 容器的 8080 端口。 如果探测成功,这个 Pod 会被标记为就绪状态,kubelet 将继续每隔 10 秒运行一次探测。
除了就绪探针,这个配置包括了一个存活探针。 kubelet 会在容器启动 15 秒后进行第一次存活探测。 与就绪探针类似,存活探针会尝试连接 goproxy 容器的 8080 端口。 如果存活探测失败,容器会被重新启动。
kubectl apply -f https://k8s.io/examples/pods/probe/tcp-liveness-readiness.yaml15 秒之后,通过看 Pod 事件来检测存活探针:
kubectl describe pod goproxy定义 gRPC 存活探针
apiVersion: v1
kind: Pod
metadata:
name: etcd-with-grpc
spec:
containers:
- name: etcd
image: registry.k8s.io/etcd:3.5.1-0
command: [ "/usr/local/bin/etcd", "--data-dir", "/var/lib/etcd", "--listen-client-urls", "http://0.0.0.0:2379", "--advertise-client-urls", "http://127.0.0.1:2379", "--log-level", "debug"]
ports:
- containerPort: 2379
livenessProbe:
grpc:
port: 2379
initialDelaySeconds: 10要使用 gRPC 探针,必须配置 port 属性。 如果要区分不同类型的探针和不同功能的探针,可以使用 service 字段。 你可以将 service 设置为 liveness,并使你的 gRPC 健康检查端点对该请求的响应与将 service 设置为 readiness 时不同。 这使你可以使用相同的端点进行不同类型的容器健康检查而不是监听两个不同的端口。 如果你想指定自己的自定义服务名称并指定探测类型,Kubernetes 项目建议你使用使用一个可以关联服务和探测类型的名称来命名。 例如:myservice-liveness(使用 - 作为分隔符)。
说明:
与 HTTP 和 TCP 探针不同,gRPC 探测不能使用按名称指定端口, 也不能自定义主机名。
配置问题(例如:错误的 port 或 service、未实现健康检查协议) 都被认作是探测失败,这一点与 HTTP 和 TCP 探针类似。
kubectl apply -f https://k8s.io/examples/pods/probe/grpc-liveness.yaml15 秒钟之后,查看 Pod 事件确认存活性检查并未失败:
kubectl describe pod etcd-with-grpc当使用 gRPC 探针时,需要注意以下一些技术细节:
- 这些探针运行时针对的是 Pod 的 IP 地址或其主机名。 请一定配置你的 gRPC 端点使之监听于 Pod 的 IP 地址之上。
- 这些探针不支持任何身份认证参数(例如
-tls)。 - 对于内置的探针而言,不存在错误代码。所有错误都被视作探测失败。
- 如果
ExecProbeTimeout特性门控被设置为false,则grpc-health-probe不会考虑timeoutSeconds设置状态(默认值为 1s), 而内置探针则会在超时时返回失败。
钩子
Kubernetes 支持 postStart 和 preStop 事件。 当一个容器启动后,Kubernetes 将立即发送 postStart 事件;在容器被终结之前, Kubernetes 将发送一个 preStop 事件。容器可以为每个事件指定一个处理程序。
- **postStart :**容器启动后
- **preStop :**容器停止前
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]在上述配置文件中,你可以看到 postStart 命令在容器的 /usr/share 目录下写入文件 message。 命令 preStop 负责优雅地终止 nginx 服务。当因为失效而导致容器终止时,这一处理方式很有用。
创建 Pod:
kubectl apply -f https://k8s.io/examples/pods/lifecycle-events.yaml验证 Pod 中的容器已经运行:
kubectl get pod lifecycle-demo使用 shell 连接到你的 Pod 里的容器:
kubectl exec -it lifecycle-demo -- /bin/bash在 shell 中,验证 postStart 处理函数创建了 message 文件:
root@lifecycle-demo:/# cat /usr/share/message命令行输出的是 postStart 处理函数所写入的文本:
Hello from the postStart handler安全上下文
Pod及容器的安全上下文
- 一组用来决定容器是如何创建和运行的约束条件,这些条件代表创建和运行容器时使用的运行时参数
- 给了用户为Pod或容器定义特权和访问控制机制
Pod和容器的安全上下文设置主要包括以下几个方面
自主访问控制DAC
容器进程运行身份及资源访问权限
Linux Capabilities
seccomp
AppArmor
SELinux
Privileged Mode
Privilege Escalation
Kubernetes支持在Pod及容器级别分别使用安全上下文
资源限制
资源需求和资源限制
资源需求(requests)
- 定义需要系统预留给该容器使用的资源最小可用值
- 容器运行时可能用不到这些额度的资源,但用到时必须确保有相应数量的资源可用
- 资源需求的定义会影响调度器的决策
资源限制(limits)
- 定义该容器可以申请使用的资源最大可用值,超出该额度的资源使用请求将被拒绝
- 该限制需要大于等于requests的值,但系统在其某项资源紧张时,会从容器那里回收其使用的超出其requests值的那部分
requests和limits定义在容器级别,主要围绕cpu、memory和hugepages三种资源
为Pod和容器分配CPU资源
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
namespace: cpu-example
spec:
containers:
- name: cpu-demo-ctr
image: vish/stress
resources:
limits:
cpu: "1"
requests:
cpu: "0.5"
args:
- -cpus
- "2"配置文件的 args 部分提供了容器启动时的参数。 -cpus "2" 参数告诉容器尝试使用 2 个 CPU。
为容器指定内存资源
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
namespace: mem-example
spec:
containers:
- name: memory-demo-ctr
image: polinux/stress
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "150M", "--vm-hang", "1"]配置文件的 args 部分提供了容器启动时的参数。 "--vm-bytes", "150M" 参数告知容器尝试分配 150 MiB 内存。
设计模型
基于容器的分布式系统中常用的3类设计模式
- 单容器模式:单一容器形式运行的应用
- 单节点模式:由强耦合的多个容器协同共生
- 多节点模式:基于特定部署单元(Pod)实现分布式算法
单节点多容器模式
一种跨容器的设计模式
目的是在单个节点之上同时运行多个共生关系的容器,因而容器管理系统需要由将它们作为一个原子单位进 行统一调度
Pod概念就是这个设计模式的实现之一
单节点多容器模式的常见实现
Sidecar模式
- Pod中的应用由主应用程序(通常是基于HTTP协议的应用程序)以及一个Sidecar容器组成
- 辅助容器用于为主容器提供辅助服务以增强主容器的功能,是主应用程序是必不可少的一部分,但却未必非得运行 为应用的一部分
Ambassador模式
- Pod中的应用由主应用程序和一个Ambassador容器组成
- 辅助容器代表主容器发送网络请求至外部环境中,因此可以将其视作主容器应用的“大使”
- 应用场景:云原生应用程序需要诸如断路、路由、计量和监视等功能,但更新已有的应用程序或现有代码库以添加 这些功能可能很困难,甚至难以实现,进程外代理便成了一种有效的解决方案
Adapter模式
- Pod中的应用由主应用程序和一个Adapter容器组成
- Adapter容器为主应用程序提供一致的接口,实现了模块重用,支持标准化和规范化主容器应用程序的输出以便于外 部服务进行聚合
Init Container模式
- 一个Pod中可以同时定义多个Init容器
- Init容器负责以不同于主容器的生命周期来完成那些必要的初始化任务,包括在文件系统上设置必要的特殊权限、 数据库模式设置或为主应用程序提供初始数据等,但这些初始化逻辑无法包含在应用程序的镜像文件中,或者出于 安全原因,应用程序镜像没有执行初始化活动的权限等等
- Init容器需要串行运行,且在所有Init容器均正常终止后,才能运行主容器
自主式Pod的创建流程
自主式Pod的终止流程
Pod创建基本流程
Pod创建完整流程

pod创建过程
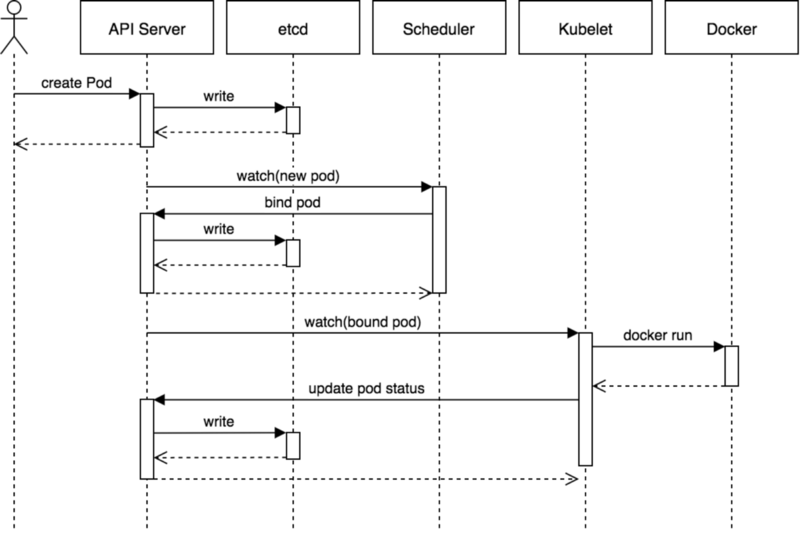
1、用户通过kubectl或其他API客户端工具提交需要创建的pod信息给apiserver 2、apiserver开始生成pod对象信息,并将信息存入ETCD,然后返回确认信息给客户端 3、apiserver开始反馈etcd中pod对象的变化,其他组件使用watch机制跟踪apiserver上的变动 4、scheduler发现有新的pod对象要创建,开始调用内部算法机制为pod分配主机,并将结果信息更新至apiserver 5、node节点上的kubectl发现有pod调度过来,尝试调用运行时启动容器,并将结果反馈apiserver 6、apiserver将收到的pod状态信息存入etcd中。
pod的终止过程
1、用户向apiserver发送删除pod对象的命令 2、apiserver中的pod对象信息会随着时间的推移而更新,在宽限期内(默认30s),pod被视为dead 3、将pod标记为terminating状态 4、kubectl在监控到pod对象为状态了就会启动pod关闭过程 5、endpoint控制器监控到pod对象的关闭行为时将其从所有匹配到此endpoint的server资源endpoint列表中删除 6、如果当前pod对象定义了preStop钩子处理器,则在其被标记为terminating后会意同步的方式启动执行 7、pod对象中的容器进程收到停止信息 8、宽限期结束后,若pod中还存在运行的进程,那么pod对象会收到立即终止的信息 9、kubelet请求apiserver将此pod资源的宽限期设置为0从而完成删除操作,此时pod对用户已不可见
pod生命周期的5中状态(也称5种相位)
Pending(挂起):API server已经创建pod,但是该pod还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程; Running(运行中):Pod内所有的容器已经创建,且至少有一个容器处于运行状态、正在启动括正在重启状态; Succeed(成功):Pod内所有容器均已退出,且不会再重启; Failed(失败):Pod内所有容器均已退出,且至少有一个容器为退出失败状态 Unknown(未知):某于某种原因apiserver无法获取该pod的状态,可能由于网络通行问题导致;
Pod常见状态及含义
| Pod状态 | 状态含义及可能的原因 |
|---|---|
| Pending | Pod未能由Scheduler完成调度,通常由于资源依赖、资源不足和调度策略无法满足等原因导致 |
| Init:N/M | Pod中定义了M个Init容器,其中N个已经运行完成,目前仍处于初始化过程中 |
| Init:Error | Init容器运行失败,需借助日志排查具体的错误原因 |
| Init:CrashLoopBackOff | Init容器启动失败,且在反复重启中,一般应该先确认配置方面的问题,再借助于日志进行排查 |
| Completed | Pod中的各容器已经正常运行完毕,各容器进程业已经终止 |
| CrashLoopBackOff | Pod启动失败,且处于反复重启过程中,通常是容器中的应用程序自身运行异常所致, 可通过查看Pod事件、容器日志和Pod配置等几方面联合排查问题 |
| ImagePullBackOff | Image拉取失败,检查Image URL是否正确,或手动测试拉取是否能够正常完成 |
| Running | Pod运行正常;但也额外存在其内部进程未正常工作的可能性,此种情况下,可通过查看Pod事件、容器日志、 Pod配置等几方面联合排查问题,或通过交互式测试验证问题所在 |
| Terminating | Pod正处于关闭过程中,若超过终止宽限期仍未能正常退出,可使用命令强制删除该Pod (命令:kubectl delete pod [\(Pod] -n [\)namespace] –grace-period=0 –force) |
| Evicted | Pod被节点驱逐,通常原因可能是由节点内存、磁盘空间、文件系统的inode、PID等资源耗尽所致,可通过Pod 的status字段确定具体的原因所在,并采取有针对性的措施扩充相应的资源 |
Pod常见错误及处理办法
| 状态 | 状态说明 | 处理办法 |
|---|---|---|
| Error | Pod启动过程中发生错误 | 一般是由于容器启动命令,参数配置错误所致,请联系镜像制作者 |
| NodeLost | Pod所在节点失联 | 检查Pod所在节点的状态 |
| Unkown | Pod所在节点失联或其他未知异常 | 检查Pod所在节点的状态 |
| Pending | Pod等待被调度 | 资源不足等原因导致,通过kubectl describe命令查看Pod事件 |
| Terminating | Pod正在被销毁 | 可增加–fore参数强制删除 |
| CrashLoopBackOff | 容器退出,Kubelet正在将它重启 | 一般是由于容器启动命令,参数配置错误所致 |
| ErrImageNeverPull | 策略禁止拉取镜像 | 拉取镜像失败,确认imagePullSecret是否正确 |
| ImagePullBackOff | 正在重试拉取 | 镜像仓库与集群的网络连通性问题 |
| RegistryUnavailable | 连接不到镜像仓库 | 联系仓库管理员 |
| ErrImagePull | 拉取镜像出错 | 联系仓库管理员,或者确认镜像名是否正确 |
| RunContainerError | 启动容器失败 | 容器参数配置异常 |
| PostStartHookError | 执行postStart hook报错 | postStart命令有误 |
| NetworkPluginNotReady | 网络插件还没有完全启动 | cni插件异常,可检查cni状态 |
标签选择器
存储卷
存储卷简介
从概念上讲,存储卷是可供Pod中的所有容器访问的目录
Pod规范中声明的存储卷来源决定了目录的创建方式、使用的存储介 质以及目录的初始内容
- 存储卷插件(存储驱动)决定了支持的后端存储介质或存储服务,例如 hostPath插件使用宿主机文件系统,而nfs插件则对接指定的NFS存储服务等
- kubelet内置支持多种存储卷插件
Pod在规范中需要指定其包含的卷以及这些卷在容器中的挂载路径
存储卷对象并非Kubernetes系统一等公民,它定义在Pod上,因而 卷本身的生命周期同Pod,但其后端的存储及相关数据的生命周期 通常要取决于存储介质
卷的使用方法
- 一个Pod可以附带多个卷,其每个容器可以在不同位置按需挂载Pod上的任意卷,或者不挂载任何卷
- Pod上的某个卷,也可以同时被该Pod内的多个容器同时挂载,以共享容器
- 如果支持,多个Pod也可以通过卷接口访问同一个后端存储单元
卷类型及卷插件
In-Tree存储卷插件
临时存储卷
- emptyDir
节点本地存储卷
- hostPath
- local
网络存储卷
- 文件系统:NFS、GlusterFS、CephFS和Cinder
- 块设备:iSCSI、FC、RBD和vSphereVolume
- 存储平台:Quobyte、PortworxVolume、StorageOS和ScaleIO
- 云存储:awsElasticBlockStore、gcePersistentDisk、azureDisk和azureFile
特殊存储卷
- Secret
- ConfigMap
- DownwardAPI和Projected
扩展接口
- CSI和FlexVolume
Out-of-Tree存储卷插件
- 经由CSI或FlexVolume接口扩展出的存储系统称为Out-of-Tree类的存储插件
卷规范及基本用法
定义存储卷
存储卷对象并非Kubernetes系统一等公民,它需要定义在 Pod上
卷本身的生命周期同Pod,但其后端的存储及相关数据的 生命周期通常要取决于存储介质
存储卷的配置由两部分组成
- 通过.spec.volumes字段定义在Pod之上的存储卷列表,它经 由特定的存储卷插件并结合特定的存储供给方的访问接口 进行定义
- 嵌套定义在容器的volumeMounts字段上的存储卷挂载列表, 它只能挂载当前Pod对象中定义的存储卷
卷的使用方法
- 一个Pod可以附带多个卷,其每个容器可以在不同位置按需挂载Pod上的任意卷,或者不挂载任何卷
- Pod上的某个卷,也可以同时被该Pod内的多个容器同时挂载以共享数据
- 如果支持,多个Pod也可以通过卷接口访问同一个后端存储单元
# 存储卷定义示例
spec:
volumes:
- name <string>
# 卷名称标识,仅可使用DNS标签格式的字符,在当前Pod中必须惟一;
VOL_TYPE <Object>
# 存储卷插件及具体的目标存储供给方的相关配置;
containers:
- name: …
image: …
volumeMounts:
- name <string>
# 要挂载的存储卷的名称,必须匹配存储卷列表中某项的定义;
mountPath <string>
# 容器文件系统上的挂载点路径;
readOnly <boolean>
# 是否挂载为只读模式,默认为否;
subPath <string>
# 挂载存储卷上的一个子目录至指定的挂载点;
subPathExpr <string>
# 挂载由指定的模式匹配到的存储卷的文件或目录至挂载点;
mountPropagation <string>
# 挂载卷的传播模式;emptyDir存储卷
emptyDir存储卷
Pod对象上的一个临时目录
在Pod对象启动时即被创建,而在Pod对象被移 除时一并被删除
通常只能用于某些特殊场景中
- 同一Pod内的多个容器间文件共享
- 作为容器数据的临时存储目录用于数据缓存系统
配置参数
medium:此目录所在的存储介质的类型,可用值为“default”或“Memory”
sizeLimit:当前存储卷的空间限额,默认值为nil, 表示不限制
root@k8s-master01:~/learning-k8s/examples/volumes# cat pod-with-emptyDir-vol.yaml
apiVersion: v1
kind: Pod
metadata:
name: pods-with-emptydir-vol
spec:
containers:
- image: ikubernetes/admin-box:v1.2
name: admin
command: ["/bin/sh", "-c"]
args: ["sleep 99999"]
resources: {}
volumeMounts:
- name: data
mountPath: /data
- image: ikubernetes/demoapp:v1.0
name: demoapp
resources: {}
volumeMounts:
- name: data
mountPath: /var/www/html
volumes:
- name: data
emptyDir:
medium: Memory
sizeLimit: 16Mi
dnsPolicy: ClusterFirst
restartPolicy: AlwayshostPath存储卷
hostPath卷
将Pod所在节点上的文件系统的某目录用作存储卷
数据的生命周期与节点相同
配置参数
- path:指定工作节点上的目录路径,必选字段
- type:指定节点之上存储类型
| type取值 | 行为 |
|---|---|
| 空字符串(默认)用于向后兼容,这意味着在安装hostPath卷之前不会执行任何检查 | |
| DirectoryOrCreate | 如果在给定路径上什么都存在,那么将根据需要创建空目录,权限设置为0755,具有与kubelet相同的组和属主信息 |
| Directory | 在给定路径上必须存在的目录 |
| FileOrCreate | 如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为0644,具有与kubelet相同的组和属主信息 |
| File | 在给定路径上必须存在的文件 |
| Socket | 在给定路径上必须存在的UNIX套接字 |
| CharDevice | 在给定路径上必须存在的字符设备 |
| BlockDevice | 在给定路径上必须存在的块设备 |
root@k8s-master01: # cat pod-with-hostpath-vol.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis
spec:
containers:
- name: redis
image: redis:7-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- name: redisdata
mountPath: /data
volumes:
- name: redisdata
hostPath:
type: DirectoryOrCreate
path: /data/redisNFS存储卷
将nfs服务器上导出(export)的文件系统用作存储卷
nfs是文件系统级共享服务,它支持多路挂载请求,可由多 个Pod对象同时用作存储卷后端
配置参数:
server :NFS服务器的IP地址或主机名,必选字段
path :NFS服务器导出(共享)的文件系统路径, 必选字段
readOnly :是否以只读方式挂载,默认为false
注意:网络卷的关联方式
网络卷首先要由主机节点挂载,然后才能暴露在Pod中
有些网络卷未必支持多主机节点同时挂载
root@k8s-master01:~ # cat pod-with-nfs-vol.yaml
apiVersion: v1
kind: Pod
metadata:
name: redis-nfs-002
spec:
containers:
- name: redis
image: redis:7-alpine
imagePullPolicy: IfNotPresent
volumeMounts:
- name: redisdata
mountPath: /data
volumes:
- name: redisdata
nfs:
server: 172.29.7.1
path: /data/redis001持久卷
PV和PVC
在Pod级别定义存储卷有两个弊端
- 卷对象的生命周期无法独立于Pod而存在
- 用户必须要足够熟悉可用的存储及其详情才能在Pod上配置和使用卷
PV和PVC可用于降低这种耦合关系
- PV(Persistent Volume)是集群级别的资源,负责将存储空间引入到集群中,通常由管理员定义
- PVC(Persistent Volume Claim)是名称空间级别的资源,由用户定义,用于在空闲的PV中申请使用符合过滤 条件的PV之一,与选定的PV是“一对一”的关系
- 用户在Pod上通过pvc插件请求绑定使用定义好的PVC资源
StorageClass资源支持PV的动态预配(Provision)
PV资源
PV是标准的资源类型,除了负责关联至后端存储系统外,它通常还需要定义支持的存储特性
- Volume Mode:当前PV卷提供的存储空间模型,分为块设备和文件系统两种
- StorageClassName:当前PV隶属的存储类;
- AccessMode:支持的访问模型,分为单路读写、多路读写和多路只读三种
- Size:当前PV允许使用的空间上限
在对象元数据上,还能够根据需要定义标签
一般需要定义回收策略:Retain、Recycle和Delete
PVC资源
- PVC也是标准的资源类型,它允许用户按需指定期望的存储特性,并以之为条件,按特定的条件顺序进行PV 过滤
- VolumeMode → LabelSelector → StorageClassName → AccessMode → Size
- 支持动态预配的存储类,还可以根据PVC的条件按需完成PV创建
使用静态PV和PVC的步骤
# 基于NFS PV资源定义示例
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-nfs-demo
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: "/data/redis02"
server: nfs.magedu.com
---
# PVC资源定义示例
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-demo
spec:
accessModes: ["ReadWriteMany"]
volumeMode: Filesystem
resources:
requests:
storage: 3Gi
limits:
storage: 10Gi
---
# 在Pod中使用PVC卷
apiVersion: v1
kind: Pod
metadata:
name: redis-dyn-pvc
spec:
containers:
- name: redis
image: redis:7-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: redisport
volumeMounts:
- mountPath: /data
name: redis-pvc-vol
volumes:
- name: redis-pvc-vol
persistentVolumeClaim:
claimName: pvc-demoStorageClass
Kubernetes支持的标准资源类型之一
为管理PV资源之便而按需创建的存储资源类别(逻辑组)
是PVC筛选PV时的过滤条件之一
为动态创建PV提供“模板”
- 需要存储服务提供管理API
- StorageClass资源上配置接入API的各种参数
- 定义在parameters字段中
- 还需要使用provisioner字段指明存储服务类型
一般由集群管理员定义,隶属集群级别
标记StorageClass成为默认的存储类
kubectl patch storageclass <your-class-name> -p '{"metadata":{"storageclass.kubernetes.io/is-default-class":"true"}}'有些存储类型默认并不支持动态PV机制
多数CSI存储都支持动态PV,且支持卷扩展和卷快照等功能
local持久卷
local卷插件用于将本地存储设备(如磁盘,分区或目录)配置为卷
- 基于网络存储的PV通常性能损耗较大
- 直接使用节点本地的SSD磁盘可获取较好的IO性能,更适用于存储类的服务,如MongoDB,Ceph等
hostPath卷在Pod被重建后可能被调试至其它节点而无法再次使用此前的数据,而基于local卷,调度器能自行完成调度绑定
- hostPath卷允许Pod访问节点上的任意路径,也存在一定程度的安全风险
基于local的PV,需要管理员通过nodeAffinity声明其定义在哪个节点
- 用户可通过PVC关联至local类型的PV;然后在Pod上配置使用该PVC即可
- 调度器将基于nodeAffinity将执行Pod调度
local卷只能关联静态置备的PV,目前尚不支持动态置备
PVC延迟绑定
配置PVC绑定local PV时,通常要创建一个StorageClass
provisioner字段的值
no-provisioner表示不使用动态置备PV,因为local插件不支持volumeBindingMode字段值
WaitForFirstConsumer表示等待消费者(Pod)申请使用PVC时(即第一次被调度时)再进行PV绑定,即延迟绑定延迟绑定机制,提供了基于消费者的需求来判定将PVC绑定至哪个PV的可能性
延迟绑定机制下,PVC创建后将处于Pending状态,直至被Pod消费
Kubernetes存储架构
存储卷的具体的管理操作由相关的控制器向卷插件发起调用请求来完成
AD控制器:负责存储设备的Attach/Detach操作
- Attach:将设备附加到目标节点
- Detach:将设备从目标节点上拆除
存储卷管理器:负责完成卷的Mount/Umount操作,以及设备的格式化操作等
PV控制器:负责PV/PVC的绑定、生命周期管理,以及存储卷的Provision/Delete操作
Scheduler:特定调度插件的调度决策会受到目标节点上的存储卷的影响
Out-of-Tree存储
CSI简介
- 容器存储接口规范,与平台无关
- 驱动程序组件
- CSI Controller:负责与存储服务的API通信从而完成后端存储的管理操作
- 由StatefulSet控制器对象编排运行,副本量需要设置为1,以保证只会该存储服务运行单 个CSI Controller实例;
- Node Plugin:也称为CSI Node,负责在节点级别完成存储卷的管理
- 由DaemonSet控制器对象编排运行,以确保每个节点上精确运行一个相关的Pod副本
- CSI Controller:负责与存储服务的API通信从而完成后端存储的管理操作
CSI存储组件和部署架构
CSI Controller:由StatefulSet控制器对象编排运行,副本量需要设置为1,以保证只会该存储服务运行单 个CSI Controller实例
Node Plugin:由DaemonSet控制器对象编排运行,以确保每个节点上精确运行一个相关的Pod副本
CSI Controller Pod中的Sidecar容器
- CSI Controller被假定为不受信任而不允许运行于Master节点之上,因此,kube-controller-manager无法借助 UnixSock套接字与之通信,而是要经由API Server进行;
- 该通用需求由Kubernetes提供的external-attacher和external-provisioner程序完成,此两者通常会以一个Sidecar容 器运行于CSI Controller Pod中
- external-attacher:负责针对CSI上的卷执行attach和detach操作,类似于CSI专用的AD Controller
- external-provisioner:负责针对CSI上的卷进行Provision和Delete操作等,类似于CSI专用的PV Controller
- CSI支持卷扩展和快照时,可能还会用到external-resizer和external-snapshotter一类的程序
CSI Node Pod中的Sidecar容器
- kubelet(实现卷的Mount/Umount操作)将UnixSock套接字与CSI Node Plugin进行通信
- 将Node Plugin注册到kubelet上,并初始化NodeID(获取从Kubernetes节点名称到CSI驱动程序NodeID的映射) 的功能由通用的node-driver-registrar程序提供,它通用运行为CSI Node Pod的Sidecar容器
CAS
容器附加存储( Container Attached Storage)
- Kubernetes的卷通常是基于外部文件系统或块存储实现,这种方案称为共享存储(Shared Storage)
- CAS则是将存储系统自身部署为kubernetes集群上的一种较新的存储解决方案
- 存储系统自身(包括存储控制器)在kubernetes上以容器化微服务的方式运行
- 使得工作负载更易于移植,且更容易根据应用程序的需求改动使用的存储
- 通常基于工作负载或者按集群部署,因此消除了共享存储的跨工作负载甚至是跨集群的爆炸半径
- 存储在CAS中的数据可以直接从集群内的容器访问,从而能显著减少读写时间
- OpenEBS是CAS存储机制的著名实现之一,由CNCF孵化
基于CAS的存储解决方案,通常包含两类组件
- 控制平面
- 负责配置卷以及其他同存储相关任务
- 由存储控制器、存储策略以及如何配置数据平面的指令组成
- 数据平面
- 接收并执行来自控制平面的有关如何保存和访问容器信息的指令
- 主要组件是实现池化存储的存储引擎,这类引擎本质上负责输入输入卷路径
- OpenEBS支持存储引擎包括Mayastor、cStor、Jiva和OpenEBS LocalPV等
CAS的重要特征
- 存储控制器分解为可以彼此独立运行的组成部分
- 每个工作负载都有自己的一个或多个控制器
OpenEBS
OpenEBS是CAS存储机制的著名实现之一,由CNCF孵化
1、安装客户端
kubernetes集群部署
先决条件:OS必须安装iSCSI客户端
# Ubuntu安装
sudo apt-get update
sudo apt-get install open-iscsi
sudo systemctl enable --now iscsid
# Centos && Redhat
yum install iscsi-initiator-utils -y2、创建openebs-operator
# 在控制平面执行以下命,部署OpenEBS基础环境,支持Local PV hostPath、Local PV device和Jiva(provisioner-iscsi)
kubectl apply -f https://openebs.github.io/charts/openebs-operator.yaml
# 检查各Pod是否正常运行
kubectl get pods -n openebs
# 检查是否创建了必要的StorageClass
kubectl get storageclassOpenEBS的基础部署会创建两个StorageClass
- openebs-hostpath:基于hostPath动态置备local PV
- openebs-device:基于NDM管理的device动态置备local PV
若要支持Jiva、cStor、Local PV ZFS和Local PV LVM等数据引擎,还需要额外部署组件
# Jiva
kubectl apply -f https://openebs.github.io/charts/jiva-operator.yaml
# cStor
kubectl apply -f https://openebs.github.io/charts/cstor-operator.yaml
# Local PV ZFS
kubectl apply -f https://openebs.github.io/charts/zfs-operator.yaml
# Local PV LVM
kubectl apply -f https://openebs.github.io/charts/lvm-operator.yaml提示:如需要用到Jiva数据引擎,则需要事先在每个节点上部署iSCSI client。Ubuntu系统的安装命令如下。
sudo apt-get update sudo apt-get install open-iscsi sudo systemctl enable --now iscsid
创建完成后,要检查是否有相应的存储类,若没有则需要手动创建
# Jiva StorageClass
# 1、创建卷策略
root@k8s-master01:~/learning-k8s/OpenEBS/jiva-csi# cat openebs-jivavolumepolicy-demo.yaml
apiVersion: openebs.io/v1alpha1
kind: JivaVolumePolicy
metadata:
name: jivavolumepolicy-demo
namespace: openebs
spec:
replicaSC: openebs-hostpath
target:
# This sets the number of replicas for high-availability
# replication factor <= no. of (CSI) nodes
replicationFactor: 2 # 指明卷副本数量,副本数一定要小于或等于工作节点数量
# disableMonitor: false
# auxResources:
# tolerations:
# resources:
# affinity:
# nodeSelector:
# priorityClassName:
# replica:
# tolerations:
# resources:
# affinity:
# nodeSelector:
# priorityClassName:
# 2、创建存储类
# cat openebs-jiva-csi-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-jiva-csi
provisioner: jiva.csi.openebs.io
allowVolumeExpansion: true
parameters:
cas-type: "jiva"
policy: "jivavolumepolicy-demo" # 指定策略名称让OpenEBS支持多路读写
解决方案:
https://github.com/openebs/dynamic-nfs-provisioner
部署:
https://github.com/openebs/dynamic-nfs-provisioner/blob/develop/docs/intro.md
kubectl apply -f https://openebs.github.io/charts/nfs-operator.yaml
执行完成后,还需要创建一个StorageClass
# 注意,NFS挂载需要安装nfs-common
apt-get install -y nfs-commonNFS CSI
1、将NFS Server部署在Kubernetes集群中(仅测试使用,生产中不建议)
kubectl create -f https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/example/nfs-provisioner/nfs-server.yaml2、安装NFS CSI Driver
# 2.1 远程部署
curl -skSL https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/install-driver.sh | bash -s master --
# 2.2 本地部署
git clone https://github.com/kubernetes-csi/csi-driver-nfs.git
cd csi-driver-nfs
./deploy/install-driver.sh master local
# 3、卸载NFS CSI Driver
# 3.1 远程脚本卸载
curl -skSL https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/uninstall-driver.sh | bash -s master --
# 3.2 本地卸载
git clone https://github.com/kubernetes-csi/csi-driver-nfs.git
cd csi-driver-nfs
git checkout master
./deploy/uninstall-driver.sh master local3、创建Storage Class
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
provisioner: nfs.csi.k8s.io
parameters:
server: nfs-server.default.svc.cluster.local # NFS Server地址
share: /
# csi.storage.k8s.io/provisioner-secret is only needed for providing mountOptions in DeleteVolume
# csi.storage.k8s.io/provisioner-secret-name: "mount-options"
# csi.storage.k8s.io/provisioner-secret-namespace: "default"
reclaimPolicy: Delete # 回收策略
volumeBindingMode: Immediate # 卷绑定模式
mountOptions:
- nfsvers=4.14、创建PVC(测试是否可以创建成功)
kubectl create -f https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/deploy/example/pvc-nfs-csi-dynamic.yamlROOK CSI
Rook是基于Ceph的云原生存储解决方案
Rook可让Ceph基于Kubernetes原生资源对象运行于 Kubernetes集群上
Rook operator负责自动化配置存储组件、监控整个 集群以确保集群的健康运行
- operator以pod形式运行,并负责启动和监视Ceph monitor pods,Ceph OSD守护进程,以及其它Ceph相 关的进程
CSI插件和Provisioner负责提供和挂载卷
Ceph相关的进程提供存储服务
Ceph提供三种存储接口
Block Storage
- PVC
Shared Filesystem
- PVC
Object Storage S3
- OBC(ObjectBucketClaim)
安装
$ git clone --single-branch --branch v1.13.7 https://github.com/rook/rook.git
cd rook/deploy/examples
kubectl create -f crds.yaml -f common.yaml -f operator.yaml
kubectl create -f cluster.yamlConfigMap && Secret
ConfigMap和Secret是Kubernetes系统上两种特殊类型的存储卷
ConfigMap用于为容器中的应用提供配置数据以定制程序的行为,而敏感 的配置信息,例如密钥、证书等则通常由Secret来配置
ConfigMap和Secret将相应的配置信息保存于资源对象中,而后在Pod对象 上支持以存储卷的形式将其挂载并加载相关的配置,从而降低了配置与镜 像文件的耦合关系,提高了镜像复用能力
Kubernetes借助于ConfigMap对象实现了将配置文件从容器镜像中解耦,从 而增强了工作负载的可移植性,使其配置更易于更改和管理,并避免了将 配置数据硬编码到Pod配置清单中
此二者都属于名称空间级别,只能被同一名称空间中的Pod引用
ConfigMap和Secret资源都是数据承载类的组件,是Kubernetes API的标准资源类型,是一等公民 主要负责提供key-value格式的数据项,其值支持
单行字符串:常用于保存环境变量值,或者命令行参数等
多行字串:常用于保存配置文件的内容
资源规范中不使用spec字段,而是直接使用特定的字段嵌套定义key-value数据
ConfigMap支持使用data或binaryData字段嵌套一至多个键值数据项
Secret支持使用data或stringData(非base64编码的明文格式)字段嵌套一至多个键值数据项
从Kubernetes v1.19版本开始,ConfigMap和Secret支持使用immutable字段创建不可变实例
在Pod中引入配置的方式
- 环境变量
- 将configMap对象上的某key的值赋值给(valueFrom)指定的环境变量
- 在Pod上基于configMap卷插件引入configmap对象
- 在Container上挂载configMap卷
- 每个kv会分别被映射为一个文件,文件名同key,value将成为文件内容
ConfigMap
创建ConfigMap对象的方法有两种
# 命令式创建
字面量:
kubectl create configmap NAME --from-literal=key1=value1
从文件加载:
kubectl create configmap NAME --from-file=[key=]/PATH/TO/FILE
从目录加载:
kubectl create configmap NAME --from-file=[key=]/PATH/TO/DIR/
# 配置文件
命令式:
kubectl create -f
声明式:
kubectl apply -f
提示:基于文件内容生成时,可以使用命令式命令以dry-run模式生成并保存
# 示例:
kubectl create configmap nginx-confs --from-file=./nginx-conf.d/myserver.conf --from-file=status.cfg=./nginx.conf.d/myserver-status.cfg引用ConfigMap对象
ConfigMap资源对象中以key-value保存的数据,在Pod中引用的方式通常有两种
环境变量
- 引用ConfigMap对象上特定的key,以valueFrom赋值给Pod上指定的环境变量
- 在Pod上使用envFrom一次性导入ConfigMap对象上的所有key-value,key(也可以统一附加特定前缀)即为环境变量名,value自动成为相应的变量值
configMap卷
- 在Pod上将ConfigMap对象引用为存储卷,而后整体由容器mount至某个目录下
-- key转为文件名,value即为相应的文件内容
- 在Pod上定义configMap卷时,仅引用其中的部分key,而后由容器mount至目录下
- 在容器上仅mount configMap卷上指定的key通过环境变量引用示例
---
# 创建ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: demoapp-config
namespace: default
data:
demoapp.port: "8080"
demoapp.host: 127.0.0.1
---
apiVersion: v1
kind: Pod
metadata:
name: configmaps-env-demo
namespace: default
spec:
containers:
- image: ikubernetes/demoapp:v1.0
name: demoapp
env: # 通过ENV引用
- name: PORT
valueFrom:
configMapKeyRef:
name: demoapp-config
key: demoapp.port
optional: false
- name: HOST
valueFrom:
configMapKeyRef:
name: demoapp-config
key: demoapp.host
optional: true通过存储卷引用
apiVersion: v1
kind: Pod
metadata:
name: configmaps-volume-demo
namespace: default
spec:
containers:
- image: nginx:alpine
name: nginx-server
volumeMounts:
- name: ngxconfs
mountPath: /etc/nginx/conf.d/
readOnly: true
volumes:
- name: ngxconfs
configMap:
name: nginx-config-files
optional: falseSecret
Secret主要用于存储密钥、OAuth令牌和 SSH 密钥等敏感信息,这些敏感信息采用base64编码保存,略好于明文存储
Secret类型
创建 Secret 时,你可以使用 Secret 资源的 type 字段,或者与其等价的 kubectl 命令行参数(如果有的话)为其设置类型。 Secret 类型有助于对 Secret 数据进行编程处理。
Kubernetes 提供若干种内置的类型,用于一些常见的使用场景。 针对这些类型,Kubernetes 所执行的合法性检查操作以及对其所实施的限制各不相同。
| 内置类型 | 用法 |
|---|---|
Opaque | 用户定义的任意数据 |
kubernetes.io/service-account-token | 服务账号令牌 |
kubernetes.io/dockercfg | ~/.dockercfg 文件的序列化形式 |
kubernetes.io/dockerconfigjson | ~/.docker/config.json 文件的序列化形式 |
kubernetes.io/basic-auth | 用于基本身份认证的凭据 |
kubernetes.io/ssh-auth | 用于 SSH 身份认证的凭据 |
kubernetes.io/tls | 用于 TLS 客户端或者服务器端的数据 |
bootstrap.kubernetes.io/token | 启动引导令牌数据 |
通过为 Secret 对象的 type 字段设置一个非空的字符串值,你也可以定义并使用自己 Secret 类型(如果 type 值为空字符串,则被视为 Opaque 类型)。
Kubernetes 并不对类型的名称作任何限制。不过,如果你要使用内置类型之一, 则你必须满足为该类型所定义的所有要求。
如果你要定义一种公开使用的 Secret 类型,请遵守 Secret 类型的约定和结构, 在类型名前面添加域名,并用 / 隔开。 例如cloudhosting.example.net/cloud-api-credentials。
注意:不同类型的Secret,在定义时支持使 用的标准字段也有所不同,例如ssh-auth类 型的Secret应该使用ssh-privatekey,而basiauth类型的Secret则需要使用username和 password等。
另外也可能存在一些特殊的用于支撑 第三方需求的类型,例如ceph的keyring信息 使用的kubernetes.io/rbd等
创建Secret资源
支持类似于ConfigMap的创建方式,但Secret有类型子命令,而且不同类型在data或stringData字段中支 持嵌套使用的key亦会有所有同
- 命令式
generic
- kubectl create secret generic NAME [--type=string] [--from-file=[key=]source] [--from-literal=key1=value1]
- 除了后面docker-registry和tls命令之外的其它类型,都可以使用该命令中的--type选项进行定义,但有些类型有key的特定要求
tls
- kubectl create secret tls NAME --cert=path/to/cert/file --key=path/to/key/file
- 通常,其保存cert文件内容的key为tls.crt,而保存private key的key为tls.key
docker-registry
- kubectl create secret docker-registry NAME --docker-username=user --docker-password=password --docker-email=email [--docker-server=string] [--from-file=[key=]source]
- 通常,从已有的json格式的文件加载生成的就是dockerconfigjson类型,命令行直接量生成的也是该类型
示例:
kubectl create secret generic mysql-root-authn --from-literal=username=root --from-literal=password=MagEdu.c0m- 声明式配置文件
# 声明一个Opaque类型的Secret
apiVersion: v1
data:
password: TWFnRWR1LmMwbQ==
username: cm9vdA==
kind: Secret
metadata:
creationTimestamp: null
name: mysql-root-authn
# 声明一个 ServiceAccount令牌Secret:
apiVersion: v1
kind: Secret
metadata:
name: secret-sa-sample
annotations:
kubernetes.io/service-account.name: "sa-name"
type: kubernetes.io/service-account-token
data:
extra: YmFyCg==
# SSH身份认证的Secret
apiVersion: v1
kind: Secret
metadata:
name: secret-ssh-auth
type: kubernetes.io/ssh-auth
data:
# 此例中的实际数据被截断
ssh-privatekey: |
MIIEpQIBAAKCAQEAulqb/Y ... 引用Secret对象
Secret资源在Pod中引用的方式同样有两种
环境变量引用
引用Secret对象上特定的key,以valueFrom赋值给Pod上指定的环境变量
在Pod上使用envFrom一次性导入Secret对象上的所有key-value,key(也可以统一附加特定前缀)即为环境变量名, value自动成为相应的变量值
# 通过环境变量引用示例
apiVersion: v1
kind: Pod
metadata:
name: secrets-env-demo
namespace: default
spec:
containers:
- name: mariadb
image: mariadb
imagePullPolicy: IfNotPresent
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-root-authn
key: passwordSecret卷引用
在Pod上将Secret对象引用为存储卷,而后整体由容器mount至某个目录下
- key转为文件名,value即为相应的文件内容
在Pod上定义Secret卷时,仅引用其中的部分key,而后由容器mount至目录下
在容器上仅mount Secret卷上指定的key
注意:容器很可能会将环境变量打印到日志中,因而不建议以环境变量方式引用Secret中的数据
# Secret卷引用示例
apiVersion: v1
kind: Pod
metadata:
name: secrets-volume-demo
namespace: default
spec:
containers:
- image: nginx:alpine
name: ngxserver
volumeMounts:
- name: nginxcerts
mountPath: /etc/nginx/certs/
readOnly: true
- name: nginxconfs
mountPath: /etc/nginx/conf.d/
readOnly: true
volumes:
- name: nginxcerts
secret:
secretName: nginx-ssl-secret
- name: nginxconfs
configMap:
name: nginx-sslvhosts-confs
optional: falseDownwardAPI
Serivce&&服务发现
Serivce
Service是Kubernetes标准的API资源类型之一,主要提供以下几种功能
为动态的Pod资源提供近似静态的流量入口
- 服务发现:通过标签选择器筛选同一名称空间下的Pod资源的标签, 完成Pod筛选。实际上是由与Service同名的Endpoint或EndpointSlice资源及控制器完成
- 流量调度:由运行各工作节点的kube-proxy根据配置的模式生成相应的流量调度规则,主要支持iptables和ipvs
持续监视着相关Pod资源的变动,并实时反映至相应的流量调度规则之上
从Service的视角来看,Kubernetes集群的每个工作节点都是动态可配置的负载均衡器
对于隶属某Service的一组Pod资源,该Service资源能够将集群中的每个工作节点配置为该组Pod的负载均衡器
客户端可以是来自集群之上的Pod,也可以是集群外部的其它端点
对于一个特定的工作节点上的某Service来说,其客户端通常有两类
该节点之上的进程,可通过该Service的Cluster IP进入
- Service_IP:Service_Port
该节点之外的端点,可经由该Service的NodePort进入
- Node_IP:Node_Port
Service类型
Service根据其所支持的客户端接入的方式,可以分为4种类型
ClusterIP:支持Service_IP:Service_Port接入,默认的类型;
NodePort:支持Node_IP:Node_Port接入,同时支持ClusterIP;
LoadBalancer:支持通过外部的LoadBalancer的LB_IP:LB_Port接入,同时支持NodePort和ClusterIP;
- Kubernetes集群外部的LoadBalancer负责将接入的流量转发至工作节点上的NodePort
- LoadBalancer需与相关的NodePort的Service生命周期联动
- LoadBalancer应该是由软件定义
- Kubernetes需要同LoadBalancer所属的管理API联动
ExternalName:
- 负责将集群外部的服务引入到集群中
- 需要借助于ClusterDNS上的CNAME资源记录完成
- 特殊类型,无需ClusterIP和NodePort
- 无须定义标签选择器发现Pod对象
# ClusterIP Service示例
---
kind: Service
apiVersion: v1
metadata:
name: demoapp-svc
namespace: default
spec:
clusterIP: 10.97.72.1
selector: # 等值类型的标签选择器,内含“与”逻辑
app: demoapp
ports: # Service的端口对象列表
- name: http
protocol: TCP # 协议,目前仅支持TCP、UDP和SCTP,默认为TCP
port: 80 # Service的端口号
targetPort: 80 # 后端目标进程的端口号或名称,名称需由Pod规范定义
# 如果你定义的 Service 将 .spec.clusterIP 设置为 "None",则 Kubernetes 不会为其分配 IP 地址,也称为无头服务(Headless Services)
---
# NodePort Service示例
kind: Service
apiVersion: v1
metadata:
name: demoapp-nodeport-svc
spec:
type: NodePort
clusterIP: 10.97.56.1 # Service的集群IP,建议由系统自动分配
selector:
app: demoapp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
nodePort: 31398 # 节点端口号,仅适用于NodePort和LoadBalancer类型
---
# LoadBalancer Service示例
apiVersion: v1
kind: Service
metadata:
name: demoapp-loadbalancer-svc
spec:
type: LoadBalancer
selector:
app: demoapp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
loadBalancerIP: 1.2.3.4 # 外部负载均衡器使用的IP地址,仅适用于LoadBlancer
---
# externalIP Service示例
apiVersion: v1
kind: Service
metadata:
name: demoapp-externalip-svc
namespace: default
spec:
type: ClusterIP
selector:
app: demoapp
ports:
- name: http
protocol: TCP
port: 80
targetPort: 80
externalIPs:
- 172.29.9.26
externalTrafficPolicy <string> # 外部流量策略处理方式,Local表示由当前节点处理,Cluster表示向集群范围调度
externalName <string> # 外部服务名称,该名称将作为Service的DNS CNAME值CoreDNS
Headless Service
Service的各类型中,ClusterIP、NodePort和LoadBalancer都为其Service配置一个ClusterIP,CoreDNS上, 这些Service对象的A记录也解析为它的ClusterIP
广义上,那些没有ClusterIP的Service则称为Headless Service,它们又可以为分两种情形
有标签选择器,或者没有标签选择器,但有着与Service对象同名的Endpoint资源
Service的DNS名称直接解析为后端各就绪状态的Pod的IP地址
调度功能也将由DNS完成
各Pod IP相关PTR记录将解析至Pod自身的名称,假设Pod IP为a.b.c.d,则其名称为a-b-c-d…svc.
这种类型也就是狭义上的Headless Service
无标签选择器且也没有与Service对象同名的Endpoint资源
- Service的DNS名称将会生成一条CNAME记录,对应值由Service对象上的spec.externalName字段指定
---
kind: Service
apiVersion: v1
metadata:
name: demoapp-headless-svc
spec:
clusterIP: None
selector:
app: demoapp
ports:
- port: 80
targetPort: 80
name: http
---
apiVersion: v1
kind: Service
metadata:
name: externalname-redis-svc
namespace: default
spec:
type: ExternalName
externalName: redis.ik8s.io
ports:
- protocol: TCP
port: 6379
targetPort: 6379
nodePort: 0
selector: {}OpenELB
OpenELB 是一个开源的云原生负载均衡器实现,可以在基于裸金属服务器、边缘以及虚拟化的 Kubernetes 环境中使用 LoadBalancer 类型的 Service 对外暴露服务。
核心功能
- BGP模式和二层网络模式下的负载均衡
- ECMP路由和负载均衡
- IP地址池管理
- 基于CRD来管理BGP配置
安装OpenELB
运行如下命令,使用kubectl部署OpenELB至Kubernetes集群。
kubectl apply -f https://raw.githubusercontent.com/openelb/openelb/master/deploy/openelb.yaml确认openelb-manager Pod已经处于Running状态,且容器已经Ready。
kubectl get pods -n openelb-system其输出的结果应该类似如下所示。
NAME READY STATUS RESTARTS AGE
openelb-admission-create-kn4fg 0/1 Completed 0 5m
openelb-admission-patch-9jfxs 0/1 Completed 2 5m
openelb-keepalive-vip-7brjl 1/1 Running 0 4m
openelb-keepalive-vip-nfpgm 1/1 Running 0 4m
openelb-keepalive-vip-vsgkx 1/1 Running 0 4m
openelb-manager-d6df4dfc4-2q4cm 1/1 Running 0 5m配置示例:layer2模式
下面的示例创建了一个Eip资源对象,它提供了一个地址池给LoadBalancer Service使用。
apiVersion: network.kubesphere.io/v1alpha2
kind: Eip
metadata:
name: eip-pool
annotations:
eip.openelb.kubesphere.io/is-default-eip: "true"
# 指定当前Eip作为向LoadBalancer Server分配地址时使用默认的eip对象;
spec:
address: 172.29.5.51-172.29.5.60
# 地址范围,也可以使用单个IP,或者带有掩码长度的网络地址;
protocol: layer2
# 要使用的OpenELB模式,支持bgp、layer2和vip三种,默认为bgp;
interface: enp1s0
# OpenELB侦听ARP或NDP请求时使用的网络接口名称,仅layer2模式下有效;
disable: false创建完成后,可使用如命令验证。
kubectl get eip eip-pool -o yaml# eip-pool.yaml
apiVersion: network.kubesphere.io/v1alpha2
kind: Eip
metadata:
name: eip-pool
annotations:
eip.openelb.kubesphere.io/is-default-eip: "true"
spec:
address: 172.29.5.51-172.29.5.80
protocol: layer2
interface: enp1s0
disable: false输出结果应该类似如下所示。
apiVersion: network.kubesphere.io/v1alpha2
kind: Eip
metadata:
annotations:
eip.openelb.kubesphere.io/is-default-eip: "true"
creationTimestamp: "2023-03-01T05:49:53Z"
finalizers:
- finalizer.ipam.kubesphere.io/v1alpha1
generation: 2
name: eip-pool
spec:
address: 172.29.5.51-172.29.5.60
interface: enp1s0
protocol: layer2
status:
firstIP: 172.29.5.51
lastIP: 172.29.5.60
poolSize: 10
ready: true
usage: 0
v4: true创建Deployment和LoadBalancer Service,测试地址池是否已经能正常向Service分配LoadBalancer IP。
kubectl create deployment demoapp --image=ikubernetes/demoapp:v1.0 --replicas=2
kubectl create service loadbalancer demoapp --tcp=80:80运行如下命令,查看service资源对象demoapp上是否自动获得了External IP。
kubectl get service demoapp其结果应该类似如下内容,这表明EIP地址分配已经能够正常进行。
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
demoapp LoadBalancer 10.97.7.114 172.29.5.51 80:30072/TCP 8m随后,即可于集群外部的客户端上通过IP地址“172.29.5.51”对demoapp服务发起访问测试。
故障排查
因为Kubernetes版本等方面的原因,部署EIP资源时遇到类似如下错误信息。
Error from server (InternalError): error when creating “eip-pool.yaml”: Internal error occurred: failed calling webhook “validate.eip.network.kubesphere.io”: failed to call webhook: Post “https://openelb-admission.openelb-system.svc:443/validate-network-kubesphere-io-v1alpha2-eip?timeout=10s”: EOF
若要忽略该类信息,可通过运行如下两个命令关闭相关的校验功能,然后再重新创建EIP资源。
kubectl delete -A ValidatingWebhookConfiguration openelb-admission
kubectl delete -A MutatingWebhookConfiguration openelb-admission清理
删除部署的测试目的Deployment和LoadBalancer Server。
kubectl delete service/demoapp deployment/demoappMetalLB
项目地址:https://metallb.universe.tf/
A network load-balancer implementation for Kubernetes using standard routing protocols.
MetalLB核心功能的实现依赖于两种机制:
- 地址分配:基于指定的地址池进行分配;
- 对外公告:让集群外部的网络了解新分配的IP地址,MetalLB使用ARP、NDP或BGP实现
安装MetalLB
# 官方建议使用IPVS而非iptables
# kube-proxy工作于ipvs模式时,必须要使用严格ARP(StrictARP)模式,因此,若有必要,先运行如下命令,配置kube-proxy。
kubectl get configmap kube-proxy -n kube-system -o yaml | \
sed -e "s/strictARP: false/strictARP: true/" | \
kubectl apply -f - -n kube-system
# 安装
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml
# https://mirror.ghproxy.com 代理地址
# 会创建一个namespeac
kubectl get pods -n metallb-system
# 创建地址池
# cat metallb-ipaddresspool.yaml
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: localip-pool
namespace: metallb-system
spec:
addresses: # 要分配地址的范围,要确定是否符合自己的网段
- 172.29.7.51-172.29.7.80
autoAssign: true
avoidBuggyIPs: true
# 创建二层通告规则
# cat metallb-l2advertisement.yaml
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: localip-pool-l2a # 地址池名称
namespace: metallb-system
spec:
ipAddressPools:
- localip-pool
interfaces:
- enp1s0 # 从哪个网卡通告
控制器
kubernetes控制器模式
API设计方式
- 命令式API
- 也称为指令式API,用户需要一步步地告诉机器该如何做(How),机器自身不具有任何“智能”,只被动接受指令
- 高度依赖用户自身理解和达成目标的能力和处理各类异常问题的经验,实现的是“命令式编程(Imperative Programming)”
- 声明式API
- 也称为申明式API,用户只需要告诉机器想要的结果(What),机器自身需要确定如何达成该目标
- 机器需要一定的“智能”,但通常只能支持事先预设和可被其理解的特定任务
- 实现的是“声明式编程(Declarative Programming)”
相较于命令式编程,声明式编程是一个更高的层次上的编程
声明式API允许用户以给出最终期望目标的方式编写代码,但具体 的执行过程(即机器智能的那部分代码),最终仍然需要以命令式 编程实现,只不过,它们可由不同的人群完成
类比来说,声明式编程的用户类似于企业的高管,只用关心和交待 最终目标;而命令式编程的用户类似于企业部门经理,他需要理解 目标的达成路径,并组织人力完成目标
Kubernetes的控制器类型
- 打包于Controller Manager中内置提供的控制器,例如Service Controller、Deployment Controller等
- 基础型、核心型控制器
- 打包运行于kube-controller-manager中
- 插件或第三方应用的专用控制器,例如Ingress插件ingress-nginx的Controller,网络插件Project Calico的 Controller等
- 高级控制器,通常需要借助于基础型控制器完成其功能
- 以Pod形式托管运行于Kubernetes之上,而且这些Pod很可能会由内置的控制器所控制
以编排Pod化运行的应用为核心的控制器,通常被统称为工作负载型控制器
- 无状态应用编排:ReplicaSet、Deployment
- 有状态应用编排:StatefulSet、第三方专用的Operator
- 系统级应用:DaemonSet
- 作业类应用:Job和CronJob
Deployment控制器
负责编排无状态应用的基础控制器是ReplicaSet,相应的资源类型 通过三个关键组件定义如何编排一个无状态应用
- replicas:期望运行的Pod副本数
- selector:标签选择器
- podTemplate:Pod模板
Deployment是建立在ReplicaSet控制器上层的更高级的控制
- 借助于ReplicaSet完成无状态应用的基本编排任务
- 它位于ReplicaSet更上面一层,基于ReplicaSet提供了滚动更新、回滚 等更为强大的应用编排功能
- 是ReplicaSet资源的编排工具
- Deployment编排ReplicaSet
- ReplicaSet编排Pod
- 但是,应该直接定义Deployment资源来编排Pod应用,ReplicaSet无须显式给出
Deployment控制器的各Pod名字以Deployment名称为前缀,中间是Pod模板的hash码,后缀是随机生成
ReplicaSet对象名称以Deployment名称为前缀,后缀是Pod模板的hash码
# Deployment示例
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-demo
spec:
replicas: 4
selector:
matchLabels:
app: demoapp
release: stable
template:
metadata:
labels:
app: demoapp
release: stable
spec:
containers:
- name: demoapp
image: ikubernetes/demoapp:v1.0
ports:
- containerPort: 80
name: http
livenessProbe:
httpGet:
path: '/livez'
port: 80
initialDelaySeconds: 5
readinessProbe:
httpGet:
path: '/readyz'
port: 80
initialDelaySeconds: 15获取Deployment资源对象的状态
root@k8s-master01:~/learning-k8s/examples/deployments# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
deployment-demo 3/4 4 3 3m28s
wordpress 3/3 3 3 15d
# NAME 名称
# READY 就绪状态的Pod数量
# UP-TO-DATE 到达期望的版本的Pod数量
# AVAILABLE 运行中并可用的Pod数量
# AGE 当前资源的创建后生存时长更新策略
Deployment控制器支持两种更新策略
滚动式更新(rolling update)
- 逐批次更新Pod的方式,支持按百分比或具体的数量定义批次规模,默认策略
- 触发条件:podTemplate的hash码变动
- 仅podTemplate的配置变动才会导致hash码改变
- replicas和selector的变更不会导致podTemplate的hash变动
重建式更新(recreate)
- 在Pod资源被删除时,使用新的模板定义被足缺失的Pod数量,完成更新
- 触发条件:现有Pod被删除
触发更新
# 最为常见的更新需求是应用升级,即镜像文件更新,常用方法
- kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 ...
- kubectl patch (-f FILENAME | TYPE NAME) [-p PATCH|--patch-file FILE] [options]
- 直接更新原配置文件,而后使用“kubectl apply”命令触发更新
上面第二和第三种方法可用于模板中任何必要配置的更新查看更新
# 更新状态:
kubectl rollout status (TYPE NAME | TYPE/NAME) [flags] [options]
$ kubectl rollout status deployment deployment-demo
# 更新历史:
kubectl rollout history (TYPE NAME | TYPE/NAME) [flags] [options]
$ kubectl rollout history deployment deployment-demo
deployment.apps/deployment-demo
REVISION CHANGE-CAUSE
1 <none>回滚更新
# 回滚到前一版本:
kubectl rollout undo (TYPE NAME | TYPE/NAME)
# 回滚到指定版本:
kubectl rollout undo (TYPE NAME | TYPE/NAME) --to-revision=X滚动更新
Deployment的滚动更新支持使用如下两个字段来配置相关的策略
maxSurge:指定升级期间存在的总Pod对象数量最多可超出期望值的个数,其值可以是0或正整数,也可以是相对于期望值的一个百分比
maxUnavailable:升级期间正常可用的Pod副本数(包括新旧版本)最多不能低于期望值的个数,其值可以是0或正整数,也可以是相对于期望值的一个百分比,默认值为1
必须以Pod为原子单位切割规模比例,且无法控制流量路由比例
更新历史默认保留十个版本
模拟金丝雀发布
# 停止滚动更新
kubectl rollout pause
# 恢复被停止的滚动更新
kubectl rollout resume扩容和缩容
扩容和缩容是ReplicaSet的功能,具体操作由ReplicaSet完成,根据应用规模的需要进行手动配置
容量管理类型
- 横向伸缩:增加或减少Pod数量
- 纵向(垂直)伸缩:调整Pod上的资源需求和资源限制
变动Deployment资源对象中的replicas字段的值即会触发应用规模的扩容或缩容
- 扩容和缩容是ReplicaSet的功能,具体操作由ReplicaSet完成
- 根据应用规模的需要进行手动配置
操作方法
- patch命令
- kubectl patch (-f FILENAME | TYPE NAME) [-p PATCH|–patch-file FILE] [options]
- 例如:kubectl patch deployment deploy-example -p ‘{“spec”:{“replicas”:3}}’
- 直接更新原配置文件,而后使用“kubectl apply”命令触发更新
自动扩缩容
- HPA(Horizontal Pod Autoscaler)控制器
- VPA(Vertical Pod Autoscaler)控制器
ReplicaSet控制器
负责编排无状态应用的基础控制器是ReplicaSet,相应的资源类型通过三个关键组件 定义如何编排一个无状态应用
- replicas:期望运行的Pod副本数
- selector:标签选择器
- matchLabels 等值
- matchExpressions: 表达式
- template:Pod模板
但是无法无损更新, ReplicaSet的升级需要大量的手工操作 所以衍生出了Deployment 升级时 Deployment 会并存多个 Replic aSet版本,
例如底层镜像更新了 需要手工删除pod 让ReplicaSet控制器 重新创建pod
各Pod的名字以ReplicaSet名称为前缀,后缀随机生成
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset-demo
spec:
minReadySeconds: 3
replicas: 2
selector:
matchLabels:
app: demoapp
release: stable
version: v1.0
template:
metadata:
labels:
app: demoapp
release: stable
version: v1.0
spec:
containers:
- name: demoapp
image: ikubernetes/demoapp:v1.0
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
path: '/livez'
port: 80
initialDelaySeconds: 5
readinessProbe:
httpGet:
path: '/readyz'
port: 80
initialDelaySeconds: 15获取ReplicaSet资源对象的状态
root@k8s-master01:~/learning-k8s/examples/deployments# kubectl get replicaset
NAME DESIRED CURRENT READY AGE
deployment-demo-6c48dd6779 4 4 0 56s
replicaset-demo 2 2 0 48s
wordpress-584df8f6bc 3 3 3 15d
# NAME 名称
# DESIRED 期望的Pod数量
# CURRENT 当前的Pod数量
# READY 就绪状态的Pod数量
# AGE 当前资源的创建后生存时长StatefulSet控制器
StatefulSet编排机制
功能:负责编排有状态(Stateful Application)应用
有状态应用会在其会话中保存客户端的数据,并且有可能会在客户端下一次的请求中使用这些数据
应用上常见的状态类型:会话状态、连接状态、配置状态、集群状态、持久性状态等
大型应用通常具有众多功能模块,这些模块通常会被设计为有状态模块和无状态模块两部分
- 业务逻辑模块一般会被设计为无状态,这些模块需要将其状态数据保存在有状态的中间件服务上,如消息队列、数据库或缓存系统等
- 无状态的业务逻辑模块易于横向扩展,有状态的后端则存在不同的难题
StatefulSet控制器自Kubernetes v1.9版本才正式引入,为实现有状态应用编排,它依赖于几个特殊设计
各Pod副本分别具有唯一的名称标识,这依赖于一个专用的Headless Service实现
基于Pod管理策略(Pod Management Policy),定义创建、删除及扩缩容等管理操作期间,施加在Pod副本上 的操作方式
- OrderedReady:创建或扩容时,顺次完成各Pod副本的创建,且要求只有前一个Pod转为Ready状态后,才能进行后一 个Pod副本的创建;删除或缩容时,逆序、依次完成相关Pod副本的终止
- Parallel:各Pod副本的创建或删除操作不存在顺序方面的要求,可同时进行
各Pod副本存储的状态数据并不相同,因而需要专用且稳定的Volume
- 基于podTemplate定义Pod模板
- 在podTemplate上使用volumeTemplate为各Pod副本动态置备PersistentVolume
Pod副本的专用名称标识
- 每个StatefulSet对象强依赖于一个专用的Headless Service对象
- StatefulSet中的各Pod副本分别拥有唯一的名称标识
- 前缀格式为“\((statefulset_name)-\)(ordinal)”
- 后缀格式为“\((service_name).\)(namespace).cluster.local”
- 各Pod的名称标识可由ClustrDNS直接解析为Pod IP
volumeTemplate
在创建Pod副本时绑定至专有的PVC
PVC的名称遵循特定的格式,从而能够与StatefulSet控制器对象的 Pod副本建立关联关系
支持从静态置备或动态置备的PV中完成绑定
删除Pod(例如缩容),并不会一并删除相关的PVC
StatefulSet存在的问题
各有状态、分布式应用在启动、扩容、缩容等运维操作上的步骤 存在差异,甚至完全不同,因而StatefulSet只能提供一个基础的 编排框架
有状态应用所需要的管理操作,需要由用户自行编写代码完成
资源规范
除了标签选择器和Pod模板,StatefulSet必须要配置一个专 用的Headless Service,而且还可能要根据需要,编写代码 完成扩容、缩容等功能所依赖的必要操作步骤;
apiVersion: apps/v1 # API群组及版本;
kind: DaemonSet # 资源类型特有标识;
metadata:
name <string> # 资源名称,在作用域中要惟一;
namespace <string> # 名称空间;DaemonSet资源隶属名称空间级别;
spec:
minReadySeconds <integer> # Pod就绪后多少秒内任一容器无crash方可视为“就绪”;
serviceName <string> # 关联的Headless Service的名称,需要事先存在;
selector <object> # 标签选择器,必须匹配template字段中Pod模板中的标签;
replicas <integer> # Pod的副本数量;
template <object> # Pod模板对象;
volumeClaimTemplates <[]Object> # 卷请求模板;
podManagementPolicy <string> # Pod管理策略,支持OrderedReady和Parallel两种,默认为前者;
revisionHistoryLimit <integer> # 滚动更新历史记录数量,默认为10;
updateStrategy <Object> # 滚动更新策略
type <string> # 滚动更新类型,可用值有OnDelete和RollingUpdate;
rollingUpdate <Object> # 滚动更新参数,专用于RollingUpdate类型;
maxUnavailable <string> # 更新期间可比期望的Pod数量缺少的数量或比例;
partition <integer> # 更新策略中的partition号码,默认为0;StatefulSet示例
apiVersion: v1
kind: Service
metadata:
name: demoapp-sts
namespace: default
spec:
clusterIP: None
ports:
- port: 80
name: http
selector:
app: demoapp
controller: sts-demo
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: sts-demo
spec:
serviceName: demoapp-sts
replicas: 2
selector:
matchLabels:
app: demoapp
controller: sts-demo
template:
metadata:
labels:
app: demoapp
controller: sts-demo
spec:
containers:
- name: demoapp
image: ikubernetes/demoapp:v1.0
ports:
- containerPort: 80
name: web
volumeMounts:
- name: appdata
mountPath: /app/data
volumeClaimTemplates:
- metadata:
name: appdata
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "nfs-csi"
resources:
requests:
storage: 2Gi更新策略
rollingUpdate:滚动更新,自动触发
onDelete:删除时更新,手动触发
滚动更新
配置策略
- maxUnavailable:定义单批次允许更新的最大副本数量
- partition :用于定义更新分区的编号,其序号大于等于该编号的Pod都将被更新,小于该分区号的都不予更 新;默认编号为0,即更新所有副本;
更新方式
- kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 …
- kubectl patch (-f FILENAME | TYPE NAME) [-p PATCH|–patch-file FILE] [options]
- 直接更新原配置文件,而后使用“kubectl apply”命令触发更新
Operator
Operator 是增强型的控制器(Controller),它扩展了Kubernetes API的功能,并基于该扩展管理复杂应用程序
- Operator 是 Kubernetes 的扩展软件, 它利用定制的资源类型来增强自动化管理应用及其组件的能力,从而扩 展了集群的行为模式
- 使用自定义资源(例如CRD)来管理应用程序及其组件
- 将应用程序视为单个对象,并提供面向该应用程序的自动化管控操作,例如部署、配置、升级、备份、故障 转移和灾难恢复等
OperatorHub:https://operatorhub.io/
DaemonSet控制器
使用DaemonSet编排应用
同Deployment相似,DaemonSet基于标签选择器管控一 组Pod副本
但是,DaemonSet用于确保所有或选定的工作节点上 都运行有一个Pod副本
- 提示:DaemonSet的根本目标在于让每个节点一个 Pod
- 有符合条件的新节点进入时,DaemonSet会将Pod自动添 加至相应节点;而节点的移出,相应的Pod副本也将被回收;
DaemonSet不需要定义replicas(Pod副本数量)
rollingUpdate 仅支持先删除一个节点上的副本 然后再去更新下一个节点
常用场景
- 特定类型的系统化应用,例如kube-proxy,以及Calico 网络插件的节点代理calico-node等
- 集群存储守护进程、集群日志收集守护进程以及节点 监控守护进程等
资源规范
与Deployment相似,DaemonSet对象也使用标签选择器和Pod模板,区 别之处在于,DaemonSet不需要定义replicas(Pod副本数量),其Pod数 量随节点数量而定;
apiVersion: apps/v1 # API群组及版本;
kind: DaemonSet # 资源类型特有标识;
metadata:
name <string> # 资源名称,在作用域中要惟一;
namespace <string> # 名称空间;DaemonSet资源隶属名称空间级别;
spec:
minReadySeconds <integer> # Pod就绪后多少秒内任一容器无crash方可视为“就绪”;
selector <object> # 标签选择器,必须匹配template字段中Pod模板中的标签;
template <object> # Pod模板对象;
revisionHistoryLimit <integer> # 滚动更新历史记录数量,默认为10;
updateStrategy <Object> # 滚动更新策略
type <string> # 滚动更新类型,可用值有OnDelete和RollingUpdate;
rollingUpdate <Object> # 滚动更新参数,专用于RollingUpdate类型;
maxUnavailable <string> # 更新期间可比期望的Pod数量缺少的数量或比例;DaemonSet示例
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-demo
namespace: default
labels:
app: prometheus
component: node-exporter
spec:
selector:
matchLabels:
app: prometheus
component: node-exporter
template:
metadata:
name: prometheus-node-exporter
labels:
app: prometheus
component: node-exporter
spec:
containers:
- image: prom/node-exporter:v1.5.0
name: prometheus-node-exporter
ports:
- name: prom-node-exp
containerPort: 9100
hostPort: 9100
livenessProbe:
tcpSocket:
port: prom-node-exp
initialDelaySeconds: 3
readinessProbe:
httpGet:
path: '/metrics'
port: prom-node-exp
scheme: HTTP
initialDelaySeconds: 5
hostNetwork: true
hostPID: true查看DaemonSet状态
# 使用kubectl get daemonset命令
root@k8s-master01:~ # kubectl get daemonset
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset-demo 3 3 0 3 0 <none> 19s
root@k8s-master01:~/learning-k8s/examples/daemonsets# kubectl get pods -l app=prometheus -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED
NODE READINESS GATES
daemonset-demo-7f8lq 0/1 ContainerCreating 0 110s 192.168.10.12 k8s-node02 <none>
<none>
daemonset-demo-b9tbd 0/1 ContainerCreating 0 110s 192.168.10.13 k8s-node03 <none>
<none>
daemonset-demo-x274c 0/1 ContainerCreating 0 110s 192.168.10.11 k8s-node01 <none>
<none>
DESIRED:期望存在的Pod副本数
AVAILABLE:可用的Pod副本数
CURRENT:当前已存在的Pod副本数
NODE SELECTOR:节点选择器,<node>表示未使用选择器,因而将适配到所有节点
READY:当前已经转为就绪状态的Pod副本数
AGE:资源已经创建的时长
UP-TO-DATE :已经更新到期望版本的Pod副本数更新策略
- rollingUpdate:滚动更新,自动触发
- onDelete:删除时更新,手动触发
滚动更新
- 配置策略:rollingUpdate更新策略支持使用maxUnavailable参数来定义单批次允许更新的最大副本数量
- 更新方式
- kubectl set image (-f FILENAME | TYPE NAME) CONTAINER_NAME_1=CONTAINER_IMAGE_1 …
- kubectl patch (-f FILENAME | TYPE NAME) [-p PATCH|–patch-file FILE] [options]
- 直接更新原配置文件,而后使用“kubectl apply”命令触发更新
Job和CronJob控制器
Job负责编排运行有结束时间的“一次性”任务,而前面的 Deployment和DaemonSet主要负责编排始终运行的守护进程类 应用;
- 控制器要确保Pod内的进程“正常(成功完成任务)”地退出
- 非正常退出的Pod可以根据需要重启,并在重试一次的次数后终止
- 有些Job是单次任务,也有些Job需要运行多次(次数通常固定)
- 有些任务支持同时创建及并行运行多个Pod以加快任务处理速度, Job控制器还允许用户自定义其并行度
需要周期性运行的Job,则由CronJob控制器负责编排
- CronJob建立在Job的功能之上,是更高层级的控制器
- 它以Job控制器完成单批次的任务编排,而后为这种Job作业提供 需要运行的周期定义
资源规范
Job资源同样需要标签选择器和Pod模板,但它不需要指定replicas,而是应该给定completions,即需要完成的作业次数,默认为1次;
- Job资源会为其Pod对象自动添加“job-name=JOB_NAME”和“controller-uid=UID”标签,并使用标签选择器完成对controller-uid标签的关联, 因此,selector并非必选字段
- Pod的命名格式:
$(job-name)-$(index)-$(random-string),其中的$(index)字段取值与completions和completionMode有关
注意:
- Job资源所在群组为“batch/v1”
- Job资源中,Pod的RestartPolicy的取值只能为Never或OnFailure
# Job资源规范
apiVersion: batch/v1 # API群组及版本;
kind: Job # 资源类型特有标识;
metadata:
name <string> # 资源名称,在作用域中要惟一;
namespace <string> # 名称空间;Job资源隶属名称空间级别;
spec:
selector <object> # 标签选择器,必须匹配template字段中Pod模板中的标签;
suspend <boolean> # 是否挂起当前Job的执行,挂起作业会重置StartTime字段的值;
template <object> # Pod模板对象;
completions <integer> # 期望的成功完成的作业次数,成功运行结束的Pod数量;
completionMode <string> # 追踪Pod完成的模式,支持Indexed和NonIndexed(默认)两种;
ttlSecondsAfterFinished <integer> # 终止状态作业的生存时长,超期将被删除;
parallelism <integer> # 作业的最大并行度,默认为1;
backoffLimit <integer> # 将作业标记为“Failed”之前的重试次数,默认为6;
activeDeadlineSeconds <integer> # 作业启动后可处于活动状态的时长;
---
# CronJob资源规范
apiVersion: batch/v1 # API群组及版本;
kind: CronJob # 资源类型特有标识;
metadata:
name <string> # 资源名称,在作用域中要惟一;
namespace <string> # 名称空间;CronJob资源隶属名称空间级别;
spec:
jobTemplate <Object> # job作业模板,必选字段;
metadata <object> # 模板元数据;
spec <object> # 作业的期望状态;
schedule <string> # 调度时间设定,必选字段;
concurrencyPolicy <string> # 并发策略,可用值有Allow、Forbid和Replace;
failedJobsHistoryLimit <integer> # 失败作业的历史记录数,默认为1;
successfulJobsHistoryLimit <integer> # 成功作业的历史记录数,默认为3;
startingDeadlineSeconds <integer> # 因错过时间点而未执行的作业的可超期时长;
suspend <boolean> # 是否挂起后续的作业,不影响当前作业,默认为false;# Job Demo
---
apiVersion: batch/v1
kind: Job
metadata:
name: job-demo
spec:
template:
spec:
containers:
- name: myjob
image: ikubernetes/admin-box:v1.2
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 60"]
restartPolicy: Never
completions: 2
ttlSecondsAfterFinished: 3600
backoffLimit: 3
activeDeadlineSeconds: 300查询Job状态
# 使用kubectl get jobs 命令
root@k8s-master01:~/learning-k8s/examples/jobs_and_cronjobs# kubectl get job
NAME COMPLETIONS DURATION AGE
job-demo 0/2 117s 117s
状态描述(示例集群中共有两个工作节点):
COMPLETIONS:已经正常完成任务并退出的Pod数量
DURATION:Job业务的实际运行时长
AGE:Job资源创建后的时长
root@k8s-master01:~/learning-k8s/examples/jobs_and_cronjobs# kubectl get pods -l job-name=job-demo -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READI
NESS GATES
job-demo-htpkr 0/1 ContainerCreating 0 2m1s <none> k8s-node01 <none> <none
>
# 使用kubectl describe jobs命令并行式Job
Job对象能够支持多个Pod的可靠、并发执行
- 编排彼此间相互通信的并行进程并非Job的设计目标,它仅用于支撑一组相互独立而又有所关联的工作任务的并行处理 -常见的场景,有如发送电子邮件、渲染视频帧、编解码文件、NoSQL数据库中扫描主键范围等
并行式Job的关键配置参数
- parallelism:任务并行度,即最大可同行运行的Pod数量,可以将其理解为工作队列的数量
- completions:总共需要完成的任务数量,即总共需要多少个相关的Pod成功完成执行,通常要大于parallelism的值
并行式Job示例
apiVersion: batch/v1
kind: Job
metadata:
name: job-para-demo
spec:
template:
spec:
containers:
- name: myjob
image: ikubernetes/admin-box:v1.2
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c", "sleep 60"]
restartPolicy: Never
completions: 12
parallelism: 2
ttlSecondsAfterFinished: 3600
backoffLimit: 3
activeDeadlineSeconds: 1200CronJob
- CronJob控制器用于管理Job资源的运行时间,它允许用户在特定的时间或以指定的间隔运行Job
- CronJob控制器的功能类似于linux操作系统的周期性任务作业计划(crontab),用于控制作业运行的时间点及周期性运行的方式:
- 仅在未来某时间点将指定的作业运行一次
- 在指定的周期性时间点重复运行指定的作业
- CronJob资源也是标准的API资源类型
注意:
在CronJob中,通配符“?”和“*”的意义相同,它们都表示任何可用的有效值
CronJob时间表语法
# ┌───────────── 分钟 (0 - 59)
# │ ┌───────────── 小时 (0 - 23)
# │ │ ┌───────────── 月的某天 (1 - 31)
# │ │ │ ┌───────────── 月份 (1 - 12)
# │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周六)
# │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
# │ │ │ │ │
# │ │ │ │ │
# * * * * *CronJob示例
apiVersion: batch/v1
kind: CronJob
metadata:
name: cronjob-demo
namespace: default
spec:
schedule: "*/2 * * * *"
jobTemplate:
metadata:
labels:
controller: cronjob-demo
spec:
parallelism: 1
completions: 1
ttlSecondsAfterFinished: 600
backoffLimit: 3
activeDeadlineSeconds: 60
template:
spec:
containers:
- name: myjob
image: ikubernetes/admin-box:v1.2
command:
- /bin/sh
- -c
- date; echo Hello from CronJob, sleep a while...; sleep 10
restartPolicy: OnFailure
startingDeadlineSeconds: 300Service Account认证鉴权
API Server及其各客户端的通信模型
API Server是Kubernetes集群的网关,是能够与etcd通信惟一入口
- kube-controller-manager、kube-scheduler、kubelet、kube-proxy,以及后续部署的集群插件CoreDNS、Project Calico等,彼此间互不通信,彼此间的所有协作均经由API Server的REST API进行,它们都是API Server的客户端
- 确保对API Server的安全访问至关重要
- 客户端对API Server的访问应经过身份验证及权限检查
- 为防止中间人攻击,各类客户端与API Server间的通信都应使用TLS进行加密
各kubelet也会监听一些套接字,提供一个小型的REST API
- 10250是具有所在节点上Pod管理权限的读写端口,应谨慎管理
- 10255仅提供只读操作,是REST API的子集
- 另外,10248是本地healthz端点使用的端口
API Server内置的访问控制机制
API Server内置了一个有着三级别的访问控制机制
认证:核验请求者身份的合法性
授权:核验请求的操作是否获得许可
准入控制:检查操作内容是否合规
插件化机制,每种访问控制机制均有一组专用的插件栈
认证:身份核验过程遵循“或”逻辑,且任何一个插件核验成功后都将不再进行后续的插件验证
- 均不成功,则失败,或以“匿名者”身份访问
- 建议禁用“匿名者”
授权:鉴权过程遵循“或”逻辑,且任何一个插件对操作的许可授权后都将不再进行后续的插件验证
- 均未许可,则拒绝请求的操作
准入控制:内容合规性检查过程遵循“与”逻辑,且无论成败,每次的操作请求都要经由所有插件的检验
- 将数据写入etcd前,负责检查内容的有效性,因此仅对“写”操作有效
- 分两类:validating(校验)和 mutating(补全或订正)
API身份认证
用户即服务请求者的身份指代,一般使用身份标识符进行识别
- 用户标识:用户名或者ID
- 用户组
Kubernetes系统的用户大体可分为 2 类
- Service Account:服务账户,指Pod内的进程访问API Server时使用的身份信息
- API Server使用ServiceAccount类型的资源对象来保存该类账号
- 认证到API Server的认证信息称为Service Account Token,它们保存于同名的专用类型的Secret对象中
- 名称空间级别
- User Account:用户账户,指非Pod类的客户端访问API Server时使用的身份标识,一般是现实中的“人”
- API Server没有为这类账户提供保存其信息的资源类型,相关的信息通常保存于外部的文件或认证系统中
- 身份核验操作可由API Server进行,也可能是由外部身份认证服务完成
- 本身非由Kubernetes管理,因而作用域为整个集群级别
不能被识别为Service Account,也不能被识别为User Account的用户,即“匿名用户”
身份认证策略
- X.509客户端证书认证
- 持有者令牌(bearer token)
- 静态令牌文件(Static Token File)
- Bootstrap令牌
- Service Account令牌
- OIDC(OpenID Connect)令牌
- Webhook令牌
- 身份认证代理(Authenticating Proxy)
- 匿名请求
X.509数字证书认证
- 在双向TLS通信中,客户端持有数字证书,而API Server信任客户端证书的颁发者
- 信任的CA,需要在kube-apiserver程序启动时,通过–client-ca-file选项传递
- 认证通过后,客户端数字证书中的CN(Common Name)即被识别为用户名,而O(Organization)被识别为组名
- kubeadm部署的Kubernetes集群,默认使用 /etc/kubernetes/pki/ca.crt 进行客户端认证
- /etc/kubernetes/pki/ca.crt是kubeadm为Kubernetes各组件间颁发数字证书的CA
静态令牌文件
- 令牌信息保存于文本文件中
- 由kube-apiserver在启动时通过–token-auth-file选项加载
- 加载完成后的文件变动,仅能通过重启程序进行重载,因此,相关的令牌会长期有效
- 客户端在HTTP请求中,通过“Authorization Bearer TOKEN”标头附带令牌令牌以完成认证
Service Account令牌
- 该认证方式将由kube-apiserver程序内置直接启用
- 它借助于经过签名的Bearer Token来验证请求
- 签名时使用的密钥可以由–service-account-key-file选项指定,也可以默认使用API Server的tls私钥
- 用于将Pod认证到API Server之上,以支持集群内的进程与API Server通信
- Kubernetes可使用ServiceAccount准入控制器自动为Pod关联ServiceAccount
OpenID Connect(OIDC)令牌
- OAuth2认证机制,通常由底层的IaaS服务所提供
Webhook令牌认证
- 是一种用于验证Bearer Token的回调机制
- 能够扩展支持外部的认证服务,例如LDAP等
身份认证代理
- 由kube-apiserver从请求报文的特定HTTP标头中识别用户身份,相应的标头名称可由特定的选项配置指定
- kube-apiserver应该基于专用的CA来验证代理服务器身份
静态令牌认证
静态令牌认证的基础配置
- 令牌信息保存于文本文件中
- 文件格式为CSV,每行定义一个用户,由“令牌、用户名、用户ID和所属的用户组”四个字段组成,用户组为可选字段
- 格式:token,user,uid, “group1,group2,group3”
- 由kube-apiserver在启动时通过–token-auth-file选项加载
- 加载完成后的文件变动,仅能通过重启程序进行重载,因此,相关的令牌会长期有效
- 客户端在HTTP请求中,通过“Authorization Bearer TOKEN”标头附带令牌令牌以完成认证
配置示例
1、生成token,命令:echo “\((openssl rand -hex 3).\)(openssl rand -hex 8)”
2、生成static token文件
3、配置kube-apiserver加载该静态令牌文件以启用相应的认证功能
4、测试,命令:curl -k -H “Authorization: Bearer TOKEN” -k https://API_SERVER:6443/api/v1/namespaces/default/pods/
X509数字证书认证
创建客户端私钥和证书签署请求,为了便于说明问题,以下操作在master节点上以/etc/kubernetes/为工作目录
1、生成私钥: (umask 077; openssl genrsa -out ./pki/mason.key 4096)
2、创建证书签署请求: openssl req -new -key ./pki/mason.key -out ./pki/mason.csr -subj “/CN=mason/O=developers”
3、由Kubernetes CA签署证书: openssl x509 -req -days 365 -CA ./pki/ca.crt -CAkey ./pki/ca.key -CAcreateserial - in ./pki/mason.csr -out ./pki/mason.crt
4、将pki目录下的mason.crt、mason.key和ca.crt复制到某部署了kubectl的主机上,即可进行测试
这里以k8s-node01为示例;只需要复制mason.crt和mason.key即可,因为集群工作节点上已经有cr.crt文件
命令:scp -rp ./pki/{mason.crt,mason.key} k8s-node01:/etc/kubernetes/pki
在k8s-node01上发起访问测试
1、使用kubectl测试:kubectl get pods –client-certificate=\(HOME/.certs/mason.crt --client-key=\)HOME/.certs/mason.key – server=https://kubeapi.magedu.com:6443/ –certificate-authority=/etc/kubernetes/pki/ca.crt
2、也可以使用curl命令进行测试
Kubeconfig
kubeconfig是YAML格式的文件,用于存储身份认证 信息,以便于客户端加载并认证到API Server
kubeconfig保存有认证到一至多个Kubernetes集群的 相关配置信息,并允许管理员按需在各配置间灵活切换
clusters:Kubernetes集群访问端点(API Server)列表
users:认证到API Server的身份凭据列表
contexts:将每一个user同可认证到的cluster建立关联 的上下文列表
current-context:当前默认使用的context
客户端程序加载的kubeconfig文件的途径及次序
- –kubeconfig选项
- KUBECONFIG环境变量:其值是包含有kubeconfig 文件的列表
- 默认路径:$HOME/.kube/config
kubeconfig文件相关操作
kubectl config SUBCOMMAND [options]
# 打印加载的kubeconfig
kubectl config view
# cluster相关的子命令
kubectl config get-clusters
kubectl config set-cluster
kubectl config delete-cluster
# user相关的子命令
kubectl config get-users
kubectl config set-credentials
kubectl config delete-user
# context相关的子命令
kubectl config get-contexts
kubectl config set-context
kubectl config delete-context
kubectl config rename-context
# current-context相关的子命令
kubectl config current-context
kubectl config use-context如何设定kubeconfig文件
1、定义cluster
2、定义User
3、定义Context
4、设定Current-Context
示例1:为静态令牌认证的用户设定一个自定义的kubeconfig
1、定义Cluster
# 提供包括集群名称、API Server URL和信任的CA的证书相关的配置;clusters配置段中的各列表项名称需要惟一;
$ kubectl config set-cluster kube-test --embed-certs=true --certificate-authority=/etc/kubernetes/pki/ca.crt --server="https://kubeapi.magedu.com:6443" --kubeconfig=$HOME/.kube/kubeusers.conf2、定义User
# 添加身份凭据,使用静态令牌文件认证的客户端提供令牌令牌即可
$ kubectl config set-credentials jerry --token="$JERRY_TOKEN" --kubeconfig=$HOME/.kube/kubeusers.conf3、定义Context
# 为用户mason的身份凭据与kube-test集群建立映射关系
$ kubectl config set-context mason@kube-test --cluster=kube-test --user=mason --kubeconfig=$HOME/.kube/kubeusers.conf4、设定Current-Context
$ kubectl config use-context mason@kube-test --kubeconfig=$HOME/.kube/kubeusers.conf示例2:将基于X509客户端证书认证的mason用户添加至kubeusers.conf文件中,同一个列表下,不同项 的名称不能相同
1、定义Cluster
# 使用不同的身份凭据访问同一集群时,集群相关的配置无须重复定义
$ kubectl config set-cluster kube-test --embed-certs=true --certificate-authority=/etc/kubernetes/pki/ca.crt --server="https://kubeapi.magedu.com:6443" --kubeconfig=$HOME/.kube/kubeusers.conf2、定义User
# 添加身份凭据,基于X509客户端证书认证时,需要提供客户端证书和私钥
$ kubectl config set-credentials mason --embed-certs=true --client-certificate=/etc/kubernetes/pki/mason.crt --clientkey=/etc/kubernetes/pki/mason.key --kubeconfig=$HOME/.kube/kubeusers.conf3、定义Context
# 为用户jerry的身份凭据与kube-test集群建立映射关系
$ kubectl config set-context jerry@kube-test --cluster=kube-test --user=jerry --kubeconfig=$HOME/.kube/kubeusers.conf4、设定Current-Context
$ kubectl config use-context jerry@kube-test --kubeconfig=$HOME/.kube/kubeusers.confKubeconfig文件合并
客户端能够通过多种途径获取到kubeconfig文件时,将遵循如下逻辑进行文件合并
- 设置了–kubeconfig参数时,则仅使用指定的文件,且不进行合并;该参数只能使用一次;
- 否则,若设置了KUBECONFIG环境变量,则将其值用作应合并的文件列表;处理规则
- 忽略不存的文件
- 遇到内容无法反序列化的文件时,将生成错误信息
- 文件列表中,第一个设定了特定值或映射键(map key)的文件是为生效文件
- 修改某个映射键的值时,将修改列表中第一个出现该键的文件中的内容
- 创建一个键时,其将保存于列表中的第一个文件中
- 若列表中指定的文件均不存在时,则自动创建列表中的最后一个文件;
- 否则 ,将使用默认的“${HOME}/.kube/config”,且不进行合并
context的判定机制
- 若使用了–context选项,则加载该选项指定要使用的上下文
- 否则,将使用合并后的kubeconfig文件中的current-context的设定
Service Account
为何需要Service Account?
- Kubernetes原生(kubernetes-native)托管运行于 Kubernetes之上,通常需要直接与API Server进行交互以获 取必要的信息
- API Server同样需要对这类来自于Pod资源中客户端程序进行身份验证,Service Account也就是设计专用于这类场景的账号
- ServiceAccount是API Server支持的标准资源类型之一
在Pod上使用Service Account
自动设定:Service Account通常由API Server自动创建并通 过 ServiceAccount准入控制器自动关联到集群中创建的每 个Pod上
自定义:在Pod规范上,使用serviceAccountName指定要 使用的特定ServiceAccount
ServiceAccount是Kubernetes API上的标准资源类型
- 基于资源对象保存ServiceAccount的数据
- 认证信息保存于ServiceAccount对象专用的Secret中(v1.23及之前的版本
- 隶属名称空间级别,专供集群上的Pod中的进程访问API Server时使用
Kubernetes基于三个组件完成Pod上serviceaccount的自动化
- ServiceAccount Admission Controller:负责完成Pod上的ServiceAccount的自动化
- 为每个名称空间生成一个默认的default ServiceAccount及其依赖到的Secret对象(如果用得到)
- 为未定义serviceAccountName的Pod资源自动附加名称空间下的serviceaccounts/default;
- 为定义了serviceAccountName的Pod资源检查其引用的目标对象是否存在
- Token Controller
- ServiceAccount Controller
提示:需要用到特殊权限时,可为Pod指定要使用的自定义ServiceAccount资源对象
ServiceAccount的Secret和Token
ServiceAccount使用专用的Secret对象(Kubernetes v1.23-)存储相关的敏感信息
- Secret对象的类型标识为“kubernetes.io/serviceaccount”
- 该Secret对象会自动附带认证到API Server用到的Token,也称为ServiceAccount Token
ServiceAccount Token的不同实现方式
Kubernetes v1.20-
- 系统自动生成专用的Secret对象,并基于secret卷插件关联至相关的Pod;
- Secret中会自动附带Token,且永久有效;
Kubernetes v1.21-v1.23:
- 系统自动生成专用的Secret对象,并通过projected卷插件关联至相关的Pod;
- Pod不会使用Secret上的Token,而是由Kubelet向TokenRequest API请求生成,默认有效期为一年,且每小时更新一次;
Kubernetes v1.24+:
- 系统不再自动生成专用的Secret对象
- 由Kubelet负责向TokenRequest API请求生成Token
ServiceAccount中的数据
ServiceAccount使用专用的Secret类型存储相关的敏感信息
ServiceAccount专用的Secret对象有三个固定的数据项,它们的键名称分别为
- ca.crt:Kubernetes CA的数字证书
- namespace:该ServiceAccount可适用的名称空间
- token:认证到API Server的令牌,其生成方式曾多次变动
Kubernetes v1.21及之后的版本中,Pod加载上面三种数据的方式,改变为基于projected卷插件,通过三 个数据源(source)分别进行
- serviceAccountToken:提供由Kubelet负责向TokenRequest API请求生成的Token
- configMap:经由kube-root-ca.crt这个ConfigMap对象的ca.crt键,引用Kubernetes CA的证书
- downwardAPI:基于fieldRef,获取当前Pod所处的名称空间
特殊场景
- 若需要一个永不过期的Token,可手动创建ServiceAccount专用类型的Secret,并将其关联到ServiceAccount之上
示例:
# 创建
$ kubectl create serviceaccount my-service-account --dry-run=client -o yaml
# 查看当前的ServiceAccount
$ kubectl get ServiceAccount
# Pod上引用ServiceAccount对象
# 仅支持引用同一名称空间下的对象
apiVersion: v1
kind: Pod
metadata:
name: …
namespace: …
spec:
serviceAccountName <string>
automountServiceAccountToken <boolean>
…权限管理
API Server内置了一个有着三级别的访问控制机制
- 认证:核验请求者身份的合法性
- 鉴权:核验请求的操作是否获得许可
- 准入控制:检查操作内容是否合规
插件化机制,每种访问控制机制均有一组专用的插件栈
- 认证:身份核验过程遵循“或”逻辑,且任何一个插件核验成功后都将不再进行后续的插件验证
- 均不成功,则失败,或以“匿名者”身份访问
- 建议禁用“匿名者”
- 鉴权:鉴权过程遵循“或”逻辑,且任何一个插件对操作的许可授权后都将不再进行后续的插件验证
- 均未许可,则拒绝请求的操作
- 准入控制:内容合规性检查过程遵循“与”逻辑,且无论成败,每次的操作请求都要经由所有插件的检验
- 将数据写入etcd前,负责检查内容的有效性,因此仅对“写”操作有效
- 分两类:validating(校验)和 mutating(补全或订正)
API Server中的鉴权框架及启用的鉴权模块负责鉴权
- 支持的鉴权模块
- Node:专用的授权模块,它基于kubelet将要运行的Pod向kubelet进行授权;
- ABAC:通过将属性(包括资源属性、用户属性、对象和环境属性等)组合 在一起的策略,将访问权限授予用户;
- RBAC:基于企业内个人用户的角色来管理对计算机或网络资源的访问的鉴权方法;
- Webhook:用于支持同Kubernetes外部的授权机制进行集成;
- 另外两个特殊的鉴权模块是AlwaysDeny和AlwaysAllow;
配置方法
- 在kube-apiserver上使用 –authorization-mode 选项进行定义
- kubeadm部署的集群,默认启用了Node和RBAC
- 多个模块彼此间以逗号分隔
RBAC
RBAC基础概念
- 实体(Entity):在RBAC也称为Subject,通常指的是User、Group或者是ServiceAccount;
- 角色(Role):承载资源操作权限的容器;
- 资源(Resource):在RBAC中也称为Object,指代Subject期望操作的目标,例如Secret、Pod及Service对象等;
- 仅限于/api/v1/…及/apis///…起始的路径;
- 其它路径对应的端点均被视作“非资源类请求(Non-Resource Requests)”,例如/api或/healthz等端点;
- 动作(Actions):Subject可以于Object上执行的特定操作,具体的可用动作取决于Kubernetes的定义;
- 资源型对象
- 只读操作:get、list、watch等
- 读写操作:create、update、patch、delete、deletecollection等
- 非资源型端点仅支持get操作
- 资源型对象
- 角色绑定(Role Binding):将角色关联至实体上,它能够将角色具体的操作权限赋予给实体;
角色的类型
- Cluster级别:称为ClusterRole,定义集群范围内的资源操作权限集合, 包括集群级别及名称空间级别的资源对象;
- Namespace级别:称为Role,定义名称空间范围内的资源操作权限集 合;
角色绑定的类型
- Cluster级别:称为ClusterRoleBinding,可以将实体(User、Group或 ServiceAccount)关联至ClusterRole;
- Namespace级别:称为RoleBinding,可以将实体关联至ClusterRole或 Role;
- 即便将Subject使用RoleBinding关联到了ClusterRole上,该角色赋予到 Subject的权限也会降级到RoleBinding所属的Namespace范围之内;
默认的ClusterRole及ClusterRoleBinding
启用RBAC鉴权模块时,API Server会自动创建一组ClusterRole和ClusterRoleBinding对象
- 多数都以“system:”为前缀,也有几个面向用户的ClusterRole未使用该前缀,如cluster-admin、admin等
- 它们都默认使用“kubernetes.io/bootstrapping: rbac-defaults”这一标签
默认的ClusterRole大体可以分为如下5个类别
- API发现相关的角色
- 包括system:basic-user、system:discovery和system:public-info-viewer
| 默认 ClusterRole | 默认 ClusterRoleBinding | 描述 |
|---|---|---|
| system:basic-user | system:authenticated 组 | 允许用户以只读的方式去访问他们自己的基本信息。在 v1.14 版本之前,这个角色在默认情况下也绑定在 system:unauthenticated 上。 |
| system:discovery | system:authenticated 组 | 允许以只读方式访问 API 发现端点,这些端点用来发现和协商 API 级别。 在 v1.14 版本之前,这个角色在默认情况下绑定在 system:unauthenticated 上。 |
| system:public-info-viewer | system:authenticated 和 system:unauthenticated 组 | 允许对集群的非敏感信息进行只读访问,此角色是在 v1.14 版本中引入的。 |
- 面向用户的角色
- 包括cluster-admin、admin、edit和view
| 默认 ClusterRole | 默认 ClusterRoleBinding | 描述 |
|---|---|---|
| cluster-admin | system:masters 组 | 允许超级用户在平台上的任何资源上执行所有操作。 当在 ClusterRoleBinding 中使用时,可以授权对集群中以及所有名字空间中的全部资源进行完全控制。 当在 RoleBinding 中使用时,可以授权控制角色绑定所在名字空间中的所有资源,包括名字空间本身。 |
| admin | 无 | 允许管理员访问权限,旨在使用 RoleBinding 在名字空间内执行授权。如果在 RoleBinding 中使用,则可授予对名字空间中的大多数资源的读/写权限, 包括创建角色和角色绑定的能力。 此角色不允许对资源配额或者名字空间本身进行写操作。 此角色也不允许对 Kubernetes v1.22+ 创建的 EndpointSlices(或 Endpoints)进行写操作。 更多信息参阅 “EndpointSlices 和 Endpoints 写权限”小节。 |
| edit | 无 | 允许对名字空间的大多数对象进行读/写操作。此角色不允许查看或者修改角色或者角色绑定。 不过,此角色可以访问 Secret,以名字空间中任何 ServiceAccount 的身份运行 Pod, 所以可以用来了解名字空间内所有服务账户的 API 访问级别。 此角色也不允许对 Kubernetes v1.22+ 创建的 EndpointSlices(或 Endpoints)进行写操作。 更多信息参阅 “EndpointSlices 和 Endpoints 写操作”小节。 |
| view | 无 | 允许对名字空间的大多数对象有只读权限。 它不允许查看角色或角色绑定。此角色不允许查看 Secret,因为读取 Secret 的内容意味着可以访问名字空间中 ServiceAccount 的凭据信息,进而允许利用名字空间中任何 ServiceAccount 的身份访问 API(这是一种特权提升)。 |
- 核心组件专用的角色
- 包括system:kube-scheduler、system:volume-scheduler、system:kube-controller-manager、system:node和system:node-proxier等
| 默认 ClusterRole | 默认 ClusterRoleBinding | 描述 |
|---|---|---|
| system:kube-scheduler | system:kube-scheduler 用户 | 允许访问 scheduler 组件所需要的资源。 |
| system:volume-scheduler | system:kube-scheduler 用户 | 允许访问 kube-scheduler 组件所需要的卷资源。 |
| system:kube-controller-manager | system:kube-controller-manager 用户 | 允许访问控制器管理器组件所需要的资源。 各个控制回路所需要的权限在控制器角色详述。 |
| system:node | 无 | 允许访问 kubelet 所需要的资源,**包括对所有 Secret 的读操作和对所有 Pod 状态对象的写操作。**你应该使用 Node 鉴权组件和 NodeRestriction 准入插件而不是 system:node 角色。同时基于 kubelet 上调度执行的 Pod 来授权 kubelet 对 API 的访问。system:node 角色的意义仅是为了与从 v1.8 之前版本升级而来的集群兼容。 |
| system:node-proxier | system:kube-proxy 用户 | 允许访问 kube-proxy 组件所需要的资源 |
- 其它组件专用的角色
- 包括system:kube-dns、system:node-bootstrapper、system:node-problem-detector和system:monitoring等
| 默认 ClusterRole | 默认 ClusterRoleBinding | 描述 |
|---|---|---|
| system:auth-delegator | 无 | 允许将身份认证和鉴权检查操作外包出去。 这种角色通常用在插件式 API 服务器上,以实现统一的身份认证和鉴权。 |
| system:heapster | 无 | 为 Heapster 组件(已弃用)定义的角色。 |
| system:kube-aggregator | 无 | 为 kube-aggregator 组件定义的角色。 |
| system:kube-dns | 在 kube-system 名字空间中的 kube-dns 服务账户 | 为 kube-dns 组件定义的角色。 |
| system:kubelet-api-admin | 无 | 允许 kubelet API 的完全访问权限。 |
| system:node-bootstrapper | 无 | 允许访问执行 kubelet TLS 启动引导 所需要的资源。 |
| system:node-problem-detector | 无 | 为 node-problem-detector 组件定义的角色。 |
| system:persistent-volume-provisioner | 无 | 允许访问大部分动态卷驱动所需要的资源。 |
| system:monitoring | system:monitoring 组 | 允许对控制平面监控端点的读取访问(例如:kube-apiserver 存活和就绪端点(/healthz、/livez、/readyz), 各个健康检查端点(/healthz/*、/livez/*、/readyz/*)和 /metrics)。 请注意,各个运行状况检查端点和度量标准端点可能会公开敏感信息。 |
- 内置控制器专用的角色
Kubernetes 控制器管理器运行内建于 Kubernetes 控制面的控制器。 当使用 --use-service-account-credentials 参数启动时,kube-controller-manager 使用单独的服务账户来启动每个控制器。 每个内置控制器都有相应的、前缀为 system:controller: 的角色。 如果控制管理器启动时未设置 --use-service-account-credentials, 它使用自己的身份凭据来运行所有的控制器,该身份必须被授予所有相关的角色。 这些角色包括:
system:controller:attachdetach-controllersystem:controller:certificate-controllersystem:controller:clusterrole-aggregation-controllersystem:controller:cronjob-controllersystem:controller:daemon-set-controllersystem:controller:deployment-controllersystem:controller:disruption-controllersystem:controller:endpoint-controllersystem:controller:expand-controllersystem:controller:generic-garbage-collectorsystem:controller:horizontal-pod-autoscalersystem:controller:job-controllersystem:controller:namespace-controllersystem:controller:node-controllersystem:controller:persistent-volume-bindersystem:controller:pod-garbage-collectorsystem:controller:pv-protection-controllersystem:controller:pvc-protection-controllersystem:controller:replicaset-controllersystem:controller:replication-controllersystem:controller:resourcequota-controllersystem:controller:root-ca-cert-publishersystem:controller:route-controllersystem:controller:service-account-controllersystem:controller:service-controllersystem:controller:statefulset-controllersystem:controller:ttl-controller
Role
方式一:命令式
格式:kubectl create role NAME –verb=verb –resource=resource.group/subresource [–resource-name=resourcename]
- verb:允许在资源上使用的操作(verb)列表
- resources.group/subresource:操作可施加的目标资源类型或子资源列表
- resourcename:特定的资源对象列表,可选
$ kubectl create role pods-viewer --verb="get,list,watch" --resource="pods" --namespace=default方式二:声明式
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
creationTimestamp: null
name: pods-viewer
namespace: default
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watchRoleBinding
命令式命令
- 命令:kubectl create rolebinding NAME –clusterrole=NAME|–role=NAME [–user=username] [–group=groupname] [–serviceaccount=namespace:serviceaccountname]
- 可以绑定到Role,也可以绑定到ClusterRole,后者会将ClusterRole的权限缩减至当前名称空间之内
- Subject可以是User、Group或者ServiceAccount
- 示例:将用户tom绑定至角色pods-viewer之上
- 命令:kubectl create rolebinding tom-attachto-pods-viewer –role=pods-viewer –user=tom –namespace=default
- 而后可测试tom用户是否可读取default名称空间内的pods资源,以及其它资源
引用ClusterRole
- 命令:kubectl create rolebinding jerry-attachto-cluster-admin –clusterrole=cluster-admin –user=jerry –namespace=test
- 而后可测试jerry用户对test及其它名称空间中的资源对象的访问权限
ClusterRole和ClusterRoleBinding
命令式命令
- ClusterRole:kubectl create clusterrole NAME –verb=verb –resource=resource.group [–resource-name=resourcename]
- ClusterRoleBinding:kubectl create clusterrolebinding NAME –clusterrole=NAME [–user=username] [– group=groupname] [–serviceaccount=namespace:serviceaccountname]
- 示例:
- kubectl create clusterrolebinding mason –clusterrole=view –group=developers
资源规范
- ClusterRole的资源规范同Role相似
- ClusterRoleBidning的资源规范跟RoleBinding相似
注意:特殊情况下,Subject –> RoleBinding –> ClusterRole
ClusterRole上的权限,被降级使用(被集群级别的RoleBinding 绑定): 集群级别资源类型的权限:失效 名称级别的资源类型的权限:收缩到当前RoleBinding所属的名称空间中,其它名称空间的都失效
示例
kubectl create role|clusterrole
kubectl create rolebind|clusterrolebinding
kubectl create role reader --verb=get,list,watch --resource=pods,services,deployments -n default --dry-run=client -o yaml
kubectl create rolebinding tom-with-reader --role=reader --user=tom -n default --dry-run=client -o yaml
kubectl create clusterrole cluster-reader --verb=get,list,watch --resource=pods,services,deployments,namespaces,persistentvolumes --dry-run=client -o yaml
kubectl create clusterrolebinding jerry-cluster-reader --clusterrole=cluster-reader --user=jerry --dry-run=client -o yaml
kubectl create rolebinding mason-cluster-reader --clusterrole=cluster-reader --user=mason -n default --dry-run=client -o yaml案例:Prometheus Server的权限需求
将Prometheus部署运行于Kubernetes之上并监控集群时,需要使用专用的ServiceAccount运行prometheus-server相关的Pod;
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/proxy
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups:
- extensions
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: prom
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: prom案例:Jenkins Master 的权限需求
运行于Kubernetes之上的Jenkins,为了能够动态创建jenkins
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins-master
namespace: jenkins
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: jenkins-master
rules:
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["services"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: jenkins-master
roleRef:
kind: ClusterRole
name: jenkins-master
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: jenkins-master
namespace: jenkinsIngress控制器
Kubernetes集群的流量管理
Service
- 基于iptables或ipvs实现的四层负载均衡机制
- 不支持基于URL等机制对HTTP/HTTPS协议进行高级路由、超时/重试、基于流量的灰度等高级流量治理机制
- 难以将多个Service流量统一管理
Ingress
由Ingress API和Ingress Controller共同组成
- 前者负责以k8s标准的资源格式定义流量调度、路由等规则
- 后者负责监视(watch)Ingress并生成自身的配置,并据 此完成流量转发
Ingress Controller非为内置的控制器,需要额外部署
- 通常以Pod形式运行于Kubernetes集群之上
- 一般应该由专用的LB Service负责为其接入集群外部流量
Ingress和Ingress Controller
Ingress
- Kubernetes上的标准API资源类型之一
- 仅定义了抽象路由配置信息,只是元数据,需要由相应的控制器动态加载
Ingress Controller
- 反向代理服务程序,需要监视API Server上Ingress资源的变动,并将其反映至自身的配置文件中
- Kubernetes的非内置的控制器,需要额外选择部署
- 实现方案有很多,包括Ingress-Nginx、HAProxy、Traefik、Gloo、Contour和Kong等
- Kubernetes支持同时部署二个或以上的数量的Ingress Controller
- Ingress资源配置可通过特定的annotation或spec中嵌套专有的字段指明期望加载该资源的Ingress Controller
- 专用的annotation:kubernetes.io/ingress.class(现阶段已经弃用)
- v1.18版本起,Ingress资源配置中增添了新字段: spec.ingressClassName,引用的IngressClass是一种特定的资源类型
Ingress需要借助于Service资源来发现后端端点
但Ingress Controller会基于Ingress的定义将流量直接发往其相关Service的后端端点,该转发过程并不会再经由Service进行
部署Ingress-nginx
# 参考网址
https://kubernetes.github.io/ingress-nginx/deploy/
# 安装
kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v1.8.2/deploy/static/provider/cloud/deploy.yaml发布多个不同应用的方法
- FQDN:基于FQDN虚拟主机
- PATH:在同一个虚拟主机上,使用不同的location,发布不同的应用;
- HTTPS:传统的方式下,tls传话是基于IP地址建立的,每个套接字仅能建立一路tls会话;
Simple fanout
在同一个FQDN下通过不同的URI完成不同应用间的流量分发
- 基于单个虚拟主机接收多个应用的流量
- 常用于将流量分发至同一个应用下的多个不同子应用,同一个应用内的流量由调度算法分发至该应用的各后端端点
- 不需要为每个应用配置专用的域名
Name based virtual hosting
为每个应用使用一个专有的主机名,并基于这些名称完成不同应用间的流量转发
- 每个FQDN对应于Ingress Controller上的一个虚拟主机的定义
- 同一组内的应用的流量,由Ingress Controller根据调度算法完成请求调度
TLS
Ingress也可以提供TLS支持,但仅限于443/TCP端口
- 若TLS配置部分指定了不同的主机,则它们会根据通过SNI TLS扩展指定的主机名
- 前提:Ingress控制器支持SNI在同一端口上复用
- TLS Secret必须包含名为tls.crt和 的密钥tls.key,它们分别含有TLS的证书和私钥
配置Ingress
命令式命令
- 创建Ingress的命令:kubectl create ingress NAME –rule=host/path=service:port[,tls[=secret]]
- 常用选项
- –annotation=[]:提供注解,格式为“annotation=value”
- –rule=[]:代理规则,格式为“host/path=service:port[,tls=secretname]”
- –class=’’:该Ingress适配的Ingress Class
准备环境:两个Service(demoapp10和demoapp11)
- 部署demoapp v1.0
- kubectl create deployment demoapp10 –image=ikubernetes/demoapp:v1.0 –replicas=3
- kubectl create service clusterip demoapp10 –tcp=80:80
- 部署demoapp v1.1
- kubectl create deployment demoapp11 –image=ikubernetes/demoapp:v1.1 –replicas=2
- kubectl create service clusterip demoapp11 –tcp=80:80
基于以上demoapp演示三种创建Ingress资源方法
Simple fanout
- 基于URI方式代理不同应用的请求时,后端应用的URI若与代理时使用的URI不同,则需要启用URL Rewrite完成URI的 重写
- Ingress-Nginx支持使用“annotation nginx.ingress.kubernetes.io/rewrite-target”注解进行
- 示例:对于发往demoapp.magedu.com的请求,将“/v10”代理至service/demoapp10,将“/v11”代理至 service/demoapp11
kubectl create ingress demo --rule="demoapp.magedu.com/v10=demoapp10:80" --rule="demoapp.magedu.com/v11=demoapp11:80" --class=nginx --annotation nginx.ingress.kubernetes.io/rewrite-target="/" - 示例2:功能同上,但使用URI的前缀匹配,而非精确匹配,且基于正则表达式模式进行url rewrite
kubectl create ingress demo --rule='demoapp.magedu.com/v10(/|$)(.*)=demoapp10:80' --rule='demoapp.magedu.com/v11(/|$)(.*)=demoapp11:80' --class=nginx --annotation nginx.ingress.kubernetes.io/rewrite-target='/$2'Name based virtual hosting
- 基于FQDN名称代理不同应用的请求时,需要事先准备好多个域名,且确保对这些域名的解析能够到达Ingress Controller
- 示例:对demoapp10.magedu.com的请求代理至service/demoapp10,对demoapp11.magedu.com请求代理至 service/demoapp11
kubectl create ingress demoapp --rule="demoapp10.magedu.com/*=demoapp10:80" --rule="demoapp11.magedu.com/*=demoapp11:80" --class=nginxTLS
- 基于TLS的Ingress要求事先准备好专用的“kubernetes.io/tls”类型的Secret对象
(umask 077; openssl genrsa -out magedu.key 2048)
openssl req -new -x509 -key magedu.key -out magedu.crt -subj /C=CN/ST=Beijing/L=Beijing/O=DevOps/CN=services.magedu.com
kubectl create secret tls tls-magedu --cert=./magedu.crt --key=./magedu.key- 创建常规的虚拟主机代理规则,同时将该主机定义为TLS类型
kubectl create ingress tls-demo --rule='demoapp.magedu.com/*=demoapp10:80,tls=tls-magedu' --class=nginx - 注意:启用tls后,该域名下的所有URI默认为强制将http请求跳转至https,若不希望使用该功能,可以使用如下注解选项
- –annotation nginx.ingress.kubernetes.io/ssl-redirect=false
Ingress资源规范
- Ingress资源规范的v1版本隶属于“networking.k8s.io”群组
基于Ingress Nginx的灰度发布
Ingress-Nginx支持配置Ingress Annotations来实现不同场景下的灰度发布和测试,它能够满足金丝雀发布、蓝绿部署与A/B测试等不 同的业务场景
基于Ingress Nginx的Canary规则
Ingress Nginx Annotations支持的Canary规则
- nginx.ingress.kubernetes.io/canary-by-header:基于该Annotation中指定Request Header进行流量切分,适用于灰度发布以及A/B测试
- 在请求报文中,若存在该Header且其值为always时,请求将会被发送到Canary版本
- 若存在该Header且其值为never时,请求将不会被发送至Canary版本
- 对于任何其它值,将忽略该Annotation指定的Header,并通过优先级将请求与其他金丝雀规则进行优先级的比较
- nginx.ingress.kubernetes.io/canary-by-header-value:基于该Annotation中指定的Request Header的值进行流量切分,标头名称则由前一个Annotation (nginx.ingress.kubernetes.io/canary-by-header)进行指定
- 请求报文中存在指定的标头,且其值与该Annotation的值匹配时,它将被路由到Canary版本
- 对于任何其它值,将忽略该Annotation
- nginx.ingress.kubernetes.io/canary-by-header-pattern
- 同canary-by-header-value的功能类似,但该Annotation基于正则表达式匹配Request Header的值
- 若该Annotation与canary-by-header-value同时存在,则该Annotation会被忽略
- nginx.ingress.kubernetes.io/canary-weight:基于服务权重进行流量切分,适用于蓝绿部署,权重范围0 - 100按百分比将请求路由到Canary Ingress中 指定的服务
- 权重为 0 意味着该金丝雀规则不会向Canary入口的服务发送任何请求
- 权重为100意味着所有请求都将被发送到 Canary 入
- nginx.ingress.kubernetes.io/canary-by-cookie:基于 cookie 的流量切分,适用于灰度发布与 A/B 测试
- cookie的值设置为always时,它将被路由到Canary入口
- cookie的值设置为 never时,请求不会被发送到Canary入口
- 对于任何其他值,将忽略 cookie 并将请求与其他金丝雀规则进行优先级的比较
规则的应用次序
- Canary规则会按特定的次序进行评估
- 次序:canary-by-header -> canary-by-cookie -> canary-weight
示例
创建deploy-demoapp
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: demoapp
name: demoapp-v10
spec:
replicas: 1
selector:
matchLabels:
app: demoapp
version: v1.0
strategy: {}
template:
metadata:
labels:
app: demoapp
version: v1.0
spec:
containers:
- image: ikubernetes/demoapp:v1.0
name: demoapp
resources: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
app: demoapp
name: demoapp-v10
spec:
ports:
- name: http-80
port: 80
protocol: TCP
targetPort: 80
selector:
app: demoapp
version: v1.0
type: ClusterIPnginx.ingress.kubernetes.io/canary-by-header
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "X-Canary"
name: demoapp-canary-by-header
spec:
rules:
- host: demoapp.magedu.com
http:
paths:
- backend:
service:
name: demoapp-v11
port:
number: 80
path: /
pathType: Prefixnginx.ingress.kubernetes.io/canary-by-header-value
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "IsVIP"
nginx.ingress.kubernetes.io/canary-by-header-value: "false"
name: demoapp-canary-by-header-value
spec:
rules:
- host: demoapp.magedu.com
http:
paths:
- backend:
service:
name: demoapp-v11
port:
number: 80
path: /
pathType: Prefixnginx.ingress.kubernetes.io/canary-by-header-pattern
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: "Username"
nginx.ingress.kubernetes.io/canary-by-header-pattern: "(vip|VIP)_.*"
name: demoapp-canary-by-header-pattern
spec:
rules:
- host: demoapp.magedu.com
http:
paths:
- backend:
service:
name: demoapp-v11
port:
number: 80
path: /
pathType: Prefixnginx.ingress.kubernetes.io/canary-weight
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "10"
name: demoapp-canary-by-weight
spec:
rules:
- host: demoapp.magedu.com
http:
paths:
- backend:
service:
name: demoapp-v11
port:
number: 80
path: /
pathType: Prefixnginx.ingress.kubernetes.io/canary-by-cookie
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-cookie: "vip_user"
name: demoapp-canary-by-cookie
spec:
rules:
- host: demoapp.magedu.com
http:
paths:
- backend:
service:
name: demoapp-v11
port:
number: 80
path: /
pathType: PrefixHelm
Helm是一款简化安装和管理Kubernetes应用程序的工具
- 可用于Kubernetes之上的应用程序管理的资源配置文件需要以特定的结构组织为Chart
- Chart代表着可由Helm管理的有着特定格式的程序包
- Chart中的资源配置文件通常以模板(go template)形式定义
- 在部署时,用户可通过向模板参数赋值实现定制化安装的目的
- 各模板参数通常也有默认值,这些默认值定义在Chart包里一个名为values.yml的文件中
类似于kubectl,Helm也是Kubernetes API Server的命令行客户端工具
- 支持kubeconfig认证文件
- 需要事先从仓库或本地加载到要使用目标Chart,并基于Chart完成应用管理
- Chart可缓存于Helm本地主机上
支持仓库管理和包管理的各类常用操作,例如Chart仓库的增、删、改、查,以及Chart包的制作、发布、搜索、下载等
Helm 中的基本概念
Chart
代表一个 Helm 包。它包含了在 Kubernetes 集群中运行应用程序、工具或服务所需的所有 YAML 格式的资源定义文件
- 模版的默认值 会放在一个values.yaml中
Repository(仓库)
它是用来存放和共享 Helm Chart 的地方,类似于存放源码的 GitHub 的 Repository,以及存放镜像的 Docker 的 Repository
Release
它是运行在 Kubernetes 集群中的 Chart 的实例。
一个 Chart 通常可以在同一个集群中安装多次。
每一次安装都会创建一个新的 Release
Helm及应用部署
Helm Client
- API Server的客户端程序
- 支持使用kubeconfig文件认证到API Server
- 从Chart Repository中下载Chart至本地缓存
- 利用values.yaml完成对Chart中的模板字串的渲染,生成API Server可接受的配置文件
- 用户可以借助于自定义的值文件和命令行选项“–set”等自定义模板字串值,从而完成自定义部署
Chart
- 主要由部署某应用需要用到的对象配置所构成的配置文件组成
- 这些配置中通常使用了模板字串,以便用户根据需要自定义以完成定制
- 可从社区中获取(https://artifacthub.io/),也可自行创建,并通过社区分发
- 需要先将Chart Repository的信息配置在Helm上才能从中下载Chart
- Chart保存在本地缓存中
Artifact Hub
- 由Helm社区维护的一个名为Artifact Hub的Web应用,旨在便于Chart的共享与分发
- 支持查询、安装和发布Kubernetes应用程序包
部署Helm
- 使用操作系统包管理器安装,支持Homebrew、Chocolatey、Scoop、GoFish和Snap等包管理器
- 直接下载适合目标平台的二进制Helm程序包,展开并放置于合适的位置即可使用
wget https://get.helm.sh/helm-v3.14.0-linux-amd64.tar.gz
tar -xvzf https://get.helm.sh/helm-v3.14.0-linux-amd64.tar.gz
mv linux-amd64/helm /usr/local/bin/
helm version常用的Helm命令
Repostory管理
repo命令,支持repository的add、list、remove、update和index等子命令
Chart管理
create、 package、pull、 push、dependency、search、show和verify等操作
Release管理
install、upgrade、get、list、history、status、rollback和uninstall等操作案例
Helm 部署 Harbor
首先,运行如下命令,添加harbor的Chart仓库。
helm repo add harbor https://helm.goharbor.io而后,创建用于部署Harbor的名称空间,例如harbor。
kubeclt create namespace harbor最后,运行如下命令,基于该仓库中的值文件“harbor-values.yaml”即可部署Harbor。
helm install harbor -f harbor-values.yaml harbor/harbor -n harbor# harbor-values.yaml
expose:
type: ingress
tls:
enabled: true
certSource: auto
ingress:
hosts:
core: registry.magedu.com
notary: notary.magedu.com
controller: default
annotations:
kubernetes.io/ingress.class: "nginx"
ipFamily:
ipv4:
enabled: true
ipv6:
enabled: false
externalURL: https://registry.magedu.com
# 持久化存储配置部分
persistence:
enabled: true
resourcePolicy: "keep"
persistentVolumeClaim: # 定义Harbor各个组件的PVC持久卷
registry: # registry组件(持久卷)
storageClass: "nfs-csi" # 前面创建的StorageClass,其它组件同样配置
accessMode: ReadWriteMany # 卷的访问模式,需要修改为ReadWriteMany
size: 5Gi
chartmuseum: # chartmuseum组件(持久卷)
storageClass: "nfs-csi"
accessMode: ReadWriteMany
size: 5Gi
jobservice:
jobLog:
storageClass: "nfs-csi"
accessMode: ReadWriteOnce
size: 1Gi
#scanDataExports:
# storageClass: "nfs-csi"
# accessMode: ReadWriteOnce
# size: 1Gi
database: # PostgreSQl数据库组件
storageClass: "nfs-csi"
accessMode: ReadWriteMany
size: 2Gi
redis: # Redis缓存组件
storageClass: "nfs-csi"
accessMode: ReadWriteMany
size: 2Gi
trivy: # Trity漏洞扫描
storageClass: "nfs-csi"
accessMode: ReadWriteMany
size: 5Gi
harborAdminPassword: "magedu.com"Helm 部署 Wordpress
MySQL
基于bitnami提供的Chart部署MySQL,传统模式是添加bitnami的Chart仓库,而后引用bitnami/mysql这一个Chart进行部署。近来,bitnami将其维护的各项目的Chart托管到了docker hub之上,因此,其Chart的引用方式亦随之发生了变化。如下示例给出了两种场景中的部署方式,而目前通常要使用后面的“基于dockerhub上的oci仓库部署”一节中描述的方法进行部署。
基于bitnami仓库的部署
首先,添加bitnami仓库
helm repo add bitnami https://charts.bitnami.com/bitnami而后,创建目标名称空间
kubectl create namespace blog示例1:部署单节点模式的MySQL:
helm install mysql \
--set auth.rootPassword=MageEdu \
--set primary.persistence.storageClass=nfs-csi \
--set auth.database=wpdb \
--set auth.username=wpuser \
--set auth.password='magedu.com' \
bitnami/mysql \
-n blog示例2:部署主从复制模式的MySQL:
helm install mysql \
--set auth.rootPassword=MageEdu \
--set global.storageClass=nfs-csi \
--set architecture=replication \
--set auth.database=wpdb \
--set auth.username=wpuser \
--set auth.password='magedu.com' \
--set secondary.replicaCount=1 \
--set auth.replicationPassword='replpass' \
bitnami/mysql \
-n blog基于dockerhub上的oci仓库部署
部署主从复制模式的MySQL,其功能类似前一小节中的示例2。
helm install mysql \
--set auth.rootPassword='MageEdu' \
--set global.storageClass=nfs-csi \
--set architecture=replication \
--set auth.database=wpdb \
--set auth.username=wpuser \
--set auth.password='magedu.com' \
--set secondary.replicaCount=1 \
--set auth.replicationPassword='replpass' \
oci://registry-1.docker.io/bitnamicharts/mysql \
-n blog --create-namespaceWordpress
使用bitnami社区的Chart部署Wordpress,其引用方式类似于前一节中的MySQL,这里也分别进行描述。
基于bitnami仓库部署
首先,添加bitnami仓库。若该步骤已经完成,则不需要重复执行。
helm repo add bitnami https://charts.bitnami.com/bitnami示例1:使用wordpress Chart中自行依赖的MariaDB作为数据库。注意修改如下命令中各参数值,以正确适配到自有环境。
helm install wordpress \
--set wordpressUsername=wpuser \
--set wordpressPassword='magedu.com' \
--set mariadb.auth.rootPassword=secretpassword \
bitnami/wordpress \
-n blog --create-namespace示例2:使用已经部署完成的现有MySQL数据库。注意修改如下命令中各参数值,以正确适配到自有环境。
helm install wordpress \
--set mariadb.enabled=false \
--set externalDatabase.host=mysql.blog.svc.cluster.local \
--set externalDatabase.user=wpuser \
--set externalDatabase.password='magedu.com' \
--set externalDatabase.database=wpdb \
--set externalDatabase.port=3306 \
--set persistence.storageClass=nfs-csi \
--set wordpressUsername=admin \
--set wordpressPassword='magedu.com' \
bitnami/wordpress \
-n blog --create-namespace示例3:使用已经部署完成的现有MySQL数据库,支持Ingress,且外部的MySQL是主从复制架构。注意修改如下命令中各参数值,以正确适配到自有环境。
helm install wordpress \
--set mariadb.enabled=false \
--set externalDatabase.host=mysql-primary.blog.svc.cluster.local \
--set externalDatabase.user=wpuser \
--set externalDatabase.password='magedu.com' \
--set externalDatabase.database=wpdb \
--set externalDatabase.port=3306 \
--set persistence.storageClass=nfs-csi \
--set ingress.enabled=true \
--set ingress.ingressClassName=nginx \
--set ingress.hostname=blog.magedu.com \
--set ingress.pathType=Prefix \
--set wordpressUsername=admin \
--set wordpressPassword='magedu.com' \
bitnami/wordpress \
-n blog --create-namespace基于dockerhub上的oci仓库部署
下面的命令示例,将使用外部的MySQL数据库,且其访问路径为:mysql-primary.blog.svc.cluster.local。注意修改如下命令中各参数值,以正确适配到自有环境。
helm install wordpress \
--set mariadb.enabled=false \
--set externalDatabase.host=mysql-primary.blog.svc.cluster.local \
--set externalDatabase.user=wpuser \
--set externalDatabase.password='magedu.com' \
--set externalDatabase.database=wpdb \
--set externalDatabase.port=3306 \
--set persistence.storageClass=nfs-csi \
--set ingress.enabled=true \
--set ingress.ingressClassName=nginx \
--set ingress.hostname=blog.magedu.com \
--set ingress.pathType=Prefix \
--set wordpressUsername=admin \
--set wordpressPassword='magedu.com' \
oci://registry-1.docker.io/bitnamicharts/wordpress \
-n blog --create-namespace扩展
openkruise
velero
网络
apt install bridge-utils
brctl show metrics-server
部署
使用以下命令部署 Metrics Server:
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml使用以下命令验证
metrics-server部署是否运行所需数量的 Pods。kubectl get deployment metrics-server -n kube-system示例输出如下。
NAME READY UP-TO-DATE AVAILABLE AGE metrics-server 1/1 1 1 6m
补充:
“Failed to scrape node” err=“Get "https://192.168.202.203:10250/metrics/resource": tls: failed to verify certificate: x509: cannot validate certificate for 192.168.202.203 because it doesn’t contain any IP SANs” node="master.example.com"
metrics-server默认使用的是hostname,但是coredns中并没有三台物理机器的hostname和IP地址的关系,需要改为使用主机IP地址;
验证客户端证书的问题,需要改为不验证;
打开文件 metrics-server-deployment.yaml ,新增一些内容,如下图,红框中为新增的内容:
140 image: registry.k8s.io/metrics-server/metrics-server:v0.7.1 141 imagePullPolicy: IfNotPresent 142 command: 143 - /metrics-server 144 - –kubelet-insecure-tls 145 - –kubelet-preferred-address-types=InternalIP
实践案例
案例一:WordPress+MySQL副本集
# 定义Mysql使用的配置文件
# cat 01-configmap-mysql.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
data:
primary.cnf: |
# Apply this config only on the primary.
[mysql]
default-character-set=utf8mb4
[mysqld]
log-bin
character-set-server=utf8mb4
[client]
default-character-set=utf8mb4
replica.cnf: |
# Apply this config only on replicas.
[mysql]
default-character-set=utf8mb4
[mysqld]
super-read-only
character-set-server=utf8mb4
[client]
default-character-set=utf8mb4
---
# 定义Mysql Service
# cat 02-services-mysql.yaml
# Headless service for stable DNS entries of StatefulSet members. 使用Headless service 前需要部署MetalLB
apiVersion: v1
kind: Service
metadata:
name: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None
selector:
app: mysql
---
# Client service for connecting to any MySQL instance for reads.
# For writes, you must instead connect to the primary: mysql-0.mysql. 程序无需读写分离的情况下不需要创建此Service
apiVersion: v1
kind: Service
metadata:
name: mysql-read
labels:
app: mysql
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql
---
# 初始化MySQL,一主两从
# cat 03-statefulset-mysql.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
spec:
selector:
matchLabels:
app: mysql
serviceName: mysql
replicas: 3
template:
metadata:
labels:
app: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7
command:
- bash
- "-c"
- |
set -ex
# Generate mysql server-id from pod ordinal index.
[[ $(cat /proc/sys/kernel/hostname) =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# Add an offset to avoid reserved server-id=0 value.
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# Copy appropriate conf.d files from config-map to emptyDir.
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/primary.cnf /mnt/conf.d/
else
cp /mnt/config-map/replica.cnf /mnt/conf.d/
fi
volumeMounts:
- name: conf
mountPath: /mnt/conf.d
- name: config-map
mountPath: /mnt/config-map
- name: clone-mysql
image: ikubernetes/xtrabackup:1.0
command:
- bash
- "-c"
- |
set -ex
# Skip the clone if data already exists.
[[ -d /var/lib/mysql/mysql ]] && exit 0
# Skip the clone on primary (ordinal index 0).
[[ $(cat /proc/sys/kernel/hostname) =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
[[ $ordinal -eq 0 ]] && exit 0
# Clone data from previous peer.
ncat --recv-only mysql-$(($ordinal-1)).mysql 3307 | xbstream -x -C /var/lib/mysql
# Prepare the backup.
xtrabackup --prepare --target-dir=/var/lib/mysql
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
containers:
- name: mysql
image: mysql:5.7
env:
- name: LANG
value: "C.UTF-8"
- name: MYSQL_ALLOW_EMPTY_PASSWORD
value: "1"
ports:
- name: mysql
containerPort: 3306
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
livenessProbe:
exec:
command: ["mysqladmin", "ping"]
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
readinessProbe:
exec:
# Check we can execute queries over TCP (skip-networking is off).
command: ["mysql", "-h", "127.0.0.1", "-e", "SELECT 1"]
initialDelaySeconds: 5
periodSeconds: 2
timeoutSeconds: 1
- name: xtrabackup
image: ikubernetes/xtrabackup:1.0
ports:
- name: xtrabackup
containerPort: 3307
command:
- bash
- "-c"
- |
set -ex
cd /var/lib/mysql
# Determine binlog position of cloned data, if any.
if [[ -f xtrabackup_slave_info && "x$(<xtrabackup_slave_info)" != "x" ]]; then
# XtraBackup already generated a partial "CHANGE MASTER TO" query
# because we're cloning from an existing replica. (Need to remove the tailing semicolon!)
cat xtrabackup_slave_info | sed -E 's/;$//g' > change_master_to.sql.in
# Ignore xtrabackup_binlog_info in this case (it's useless).
rm -f xtrabackup_slave_info xtrabackup_binlog_info
elif [[ -f xtrabackup_binlog_info ]]; then
# We're cloning directly from primary. Parse binlog position.
[[ `cat xtrabackup_binlog_info` =~ ^(.*?)[[:space:]]+(.*?)$ ]] || exit 1
rm -f xtrabackup_binlog_info xtrabackup_slave_info
echo "CHANGE MASTER TO MASTER_LOG_FILE='${BASH_REMATCH[1]}',\
MASTER_LOG_POS=${BASH_REMATCH[2]}" > change_master_to.sql.in
fi
# Check if we need to complete a clone by starting replication.
if [[ -f change_master_to.sql.in ]]; then
echo "Waiting for mysqld to be ready (accepting connections)"
until mysql -h 127.0.0.1 -e "SELECT 1"; do sleep 1; done
echo "Initializing replication from clone position"
mysql -h 127.0.0.1 \
-e "$(<change_master_to.sql.in), \
MASTER_HOST='mysql-0.mysql', \
MASTER_USER='root', \
MASTER_PASSWORD='', \
MASTER_CONNECT_RETRY=10; \
START SLAVE;" || exit 1
# In case of container restart, attempt this at-most-once.
mv change_master_to.sql.in change_master_to.sql.orig
fi
# Start a server to send backups when requested by peers.
exec ncat --listen --keep-open --send-only --max-conns=1 3307 -c \
"xtrabackup --backup --slave-info --stream=xbstream --host=127.0.0.1 --user=root"
volumeMounts:
- name: data
mountPath: /var/lib/mysql
subPath: mysql
- name: conf
mountPath: /etc/mysql/conf.d
volumes:
- name: conf
emptyDir: {}
- name: config-map
configMap:
name: mysql
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"] # 单路读写
storageClassName: "openebs-hostpath"
resources:
requests:
storage: 10Gi
# 创建WordPress需要使用的MYSQL账号,检测从节点是否能够自动复制
kubectl exec -it mysql-0 -c mysql -- /bin/bash
CREATE DATABASE wpdb;
CREATE USER wpuser@'%' IDENTIFIED BY 'wppass';
GRANT ALL PRIVILEGES ON wpdb.* TO wpuser@'%';
FLUSH PRIVILEGES;
mysql-0.mysql.default.svc.cluster.local.
# 部署WordPress 创建Secret
kubectl create secret generic mysql-secret --from-literal=wordpress.db=wpdb --from-literal=wordpress.username=wpuser --from-literal=wordpress.password=wppass
apiVersion: v1
data:
wordpress.db: d3BkYg==
wordpress.password: d3BwYXNz
wordpress.username: d3B1c2Vy
kind: Secret
metadata:
creationTimestamp: null
name: mysql-secret
---
# 创建WordPress service
# cat 05-wordpress-service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: wordpress
name: wordpress
namespace: blog
spec:
ports:
- name: 80-80
port: 80
protocol: TCP
targetPort: 80
selector:
app: wordpress
type: LoadBalancer
---
# 创建wordPress PVC
# cat 06-pvc-wordpress.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wordpress-pvc
namespace: blog
spec:
accessModes: ["ReadWriteMany"]
volumeMode: Filesystem
resources:
requests:
storage: 5Gi
storageClassName: openebs-rwx
---
# 创建WordPress容器
# cat 07-deployment-wordpress.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: wordpress
name: wordpress
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: wordpress
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
template:
metadata:
labels:
app: wordpress
spec:
containers:
- image: wordpress:6-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: mysql-0.mysql
- name: WORDPRESS_DB_NAME
valueFrom:
secretKeyRef:
name: mysql-secret
key: wordpress.db
- name: WORDPRESS_DB_USER
valueFrom:
secretKeyRef:
name: mysql-secret
key: wordpress.username
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-secret
key: wordpress.password
volumeMounts:
- name: data
mountPath: /var/www/html/
volumes:
- name: data
persistentVolumeClaim:
claimName: wordpress-pvc如何创建测试容器
kubectl run client-$RANDOM --image=ikubernetes/admin-box:v1.2 --restart=Never --rm -it --command /bin/bash 案例二:部署ECK集群
项目地址:
https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-deploy-eck.html
# 1、将资源类型加载到集群中,可以使用kubectl get crd(kubectl api-resources)查看是否创建成功
kubectl create -f https://download.elastic.co/downloads/eck/2.10.0/crds.yaml
# 2、安装Operator的RBAC规则
kubectl apply -f https://download.elastic.co/downloads/eck/2.10.0/operator.yaml
# 3、创建elasticsearch集群
# cat elasticsearch-myes-cluster.yaml
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: myes
namespace: elastic-system
spec:
version: 8.11.3
nodeSets:
- name: default
count: 3
config:
node.store.allow_mmap: false
volumeClaimTemplates:
- metadata:
name: elasticsearch-data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
storageClassName: openebs-hostpath
---
# 4、创建Kibana
# cat kibana-myes.yaml
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana
namespace: elastic-system
spec:
version: 8.11.3
count: 1
elasticsearchRef:
name: "myes"
http:
tls:
selfSignedCertificate:
disabled: true
service:
spec:
type: LoadBalancer
---
# 5、创建Filebeat
# cat beats-filebeat.yaml
apiVersion: beat.k8s.elastic.co/v1beta1
kind: Beat
metadata:
name: filebeat
namespace: elastic-system
spec:
type: filebeat
version: 8.11.3
elasticsearchRef:
name: "myes"
kibanaRef:
name: "kibana"
config:
filebeat:
autodiscover:
providers:
- type: kubernetes
node: ${NODE_NAME}
hints:
enabled: true
default_config:
type: container
paths:
- /var/log/containers/*${data.kubernetes.container.id}.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
- drop_event.when:
or:
- equals:
kubernetes.namespace: "kube-system"
- equals:
kubernetes.namespace: "logging"
- equals:
kubernetes.namespace: "ingress-nginx"
- equals:
kubernetes.namespace: "kube-node-lease"
- equals:
kubernetes.namespace: "elastic-system"
daemonSet:
podTemplate:
spec:
serviceAccountName: filebeat
automountServiceAccountToken: true
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirstWithHostNet
hostNetwork: true # Allows to provide richer host metadata
containers:
- name: filebeat
securityContext:
runAsUser: 0
# If using Red Hat OpenShift uncomment this:
#privileged: true
volumeMounts:
- name: varlogcontainers
mountPath: /var/log/containers
- name: varlogpods
mountPath: /var/log/pods
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumes:
- name: varlogcontainers
hostPath:
path: /var/log/containers
- name: varlogpods
hostPath:
path: /var/log/pods
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: filebeat
rules:
- apiGroups: [""] # "" indicates the core API group
resources:
- namespaces
- pods
- nodes
verbs:
- get
- watch
- list
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: elastic-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: elastic-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
---案例三:部署Gitlab
案例四:部署Jenkins
1、创建专用名称空间
# 01-namespace-jenkins.yaml
---
apiVersion: v1
kind: Namespace
metadata:
name: jenkins2、准备PVC
# 02-pvc-jenkins.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: jenkins-pvc
namespace: jenkins
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: openebs-rwx3、授权用户所需的权限
# 03-rbac-jenkins.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: jenkins-master
namespace: jenkins
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: jenkins-master
rules:
- apiGroups: ["extensions", "apps"]
resources: ["deployments"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["services"]
verbs: ["create", "delete", "get", "list", "watch", "patch", "update"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["create","delete","get","list","patch","update","watch"]
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get","list","watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: jenkins-master
roleRef:
kind: ClusterRole
name: jenkins-master
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: jenkins-master
namespace: jenkins4、创建Jenkins Deployment控制器
# 04-deploy-jenkins.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jenkins
namespace: jenkins
spec:
replicas: 1
selector:
matchLabels:
app: jenkins
template:
metadata:
labels:
app: jenkins
spec:
serviceAccountName: jenkins-master
volumes:
- name: jenkins-store
persistentVolumeClaim:
claimName: jenkins-pvc
initContainers:
- name: fix-permissions
image: alpine
command: ["sh", "-c", "chown -R 1000:1000 /var/jenkins_home/"]
securityContext:
privileged: true
volumeMounts:
- name: jenkins-store
mountPath: /var/jenkins_home/
containers:
- name: jenkins
image: jenkins/jenkins:jdk17
#image: jenkins/jenkins:lts-jdk11
volumeMounts:
- name: jenkins-store
mountPath: /var/jenkins_home/
imagePullPolicy: IfNotPresent
env:
- name: JAVA_OPTS
value: -XshowSettings:vm -Dhudson.slaves.NodeProvisioner.initialDelay=0 -Dhudson.slaves.NodeProvisioner.MARGIN=50 -Dhudson.slaves.NodeProvisioner.MARGIN0=0.85 -Duser.timezone=Asia/Shanghai -Djenkins.install.runSetupWizard=true
ports:
- containerPort: 8080
name: web
protocol: TCP
- containerPort: 50000
name: agent
protocol: TCP5、创建service 关联至后端Jenkins
# 05-service-jenkins.yaml
---
apiVersion: v1
kind: Service
metadata:
name: jenkins
namespace: jenkins
labels:
app: jenkins
spec:
selector:
app: jenkins
type: NodePort
ports:
- name: http
port: 8080
targetPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: jenkins-jnlp
namespace: jenkins
labels:
app: jenkins
spec:
selector:
app: jenkins
ports:
- name: agent
port: 50000
targetPort: 500006、创建maven需要的PVC
# 06-pvc-maven-cache.yaml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-maven-cache
namespace: jenkins
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
storageClassName: openebs-rwx7、创建Ingress,将Jenkins对外发布出去
# 07-ingress-jenkins.yaml
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: jenkins
namespace: jenkins
spec:
ingressClassName: nginx
rules:
- host: cicd.magedu.com
http:
paths:
- backend:
service:
name: jenkins
port:
number: 8080
path: /
pathType: Prefix
- host: jenkins.magedu.com
http:
paths:
- backend:
service:
name: jenkins
port:
number: 8080
path: /
pathType: Prefix获取Jenkins的解锁密码
kubectl logs jenkins-7dbbcb8cb9-7ccq7 -n jenkins设定Jenkins能够解析外部域名(可选)
修改coredns的configmap类似如下内容,以确保集群内部能解析Jenkins服务的名称jenkins.magedu.com和jenkins-jnlp.magedu.com,且自动将其解析为相应Service的ClusterIP。
apiVersion: v1
kind: ConfigMap
metadata:
name: coredns
namespace: kube-system
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
rewrite stop {
name regex (jenkins.*)\.magedu\.com {1}.jenkins.svc.cluster.local
answer (jenkins.*)\.jenkins\.svc\.cluster\.local {1}.magedu.com
}
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}Pipline示例
第一个:测试于Pod中运行slave
// Author: "MageEdu <[email protected]>"
// Site: www.magedu.com
pipeline {
agent {
kubernetes {
inheritFrom 'jenkins-slave'
}
}
stages {
stage('Testing...') {
steps {
sh 'java -version'
}
}
}
}第二个:测试maven构建环境
pipeline {
agent {
kubernetes {
inheritFrom 'maven-3.8'
}
}
stages {
stage('Build...') {
steps {
container('maven') {
sh 'mvn -version'
}
}
}
}
}第三个:测试docker in docker环境
pipeline {
agent {
kubernetes {
inheritFrom 'maven-and-docker'
}
}
stages {
stage('maven version') {
steps {
container('maven') {
sh 'mvn -version'
}
}
}
stage('docker info') {
steps {
container('docker') {
sh 'docker info'
}
}
}
}
}